4.7 KiB
古语有云"工欲善其事,必先利器","磨刀不误砍柴工"...
为了让每位用户(尤其是小白)尽量避免踩坑,节省更多时间,特此总结一篇避坑指南,在正式使用EE之前,不妨花三五分钟学习一下,可以帮各位在使用中避免踩坑,从而节省大量时间.
1.ES版本及SpringBoot版本
由于我们底层用了ES官方的RestHighLevelClient,所以对ES版本有要求,底层用的RestHighLevelClient版本为7.10,所以对7.10的es兼容性最好,目前实测下来ES版本为7.x 都可以完美兼容.
底层使用的Springboot版本为2.5.4,所以我们推荐用户springboot版本也用2.5.4,由于我们对Springboot的依赖模块比较少,目前实测下来2.3.x-2.6.x的Springboot都可以完美兼容,更低或者更高的版本没有实测,用户可自行测试,我们也不清楚springboot2.5.4具体能向下和向上兼容到什么版本,总之还是推荐尽量和框架内置版本保持一致.
2.ES索引的keyword类型和text类型
对ES索引类型已经了解的可直接跳过此段介绍.
ES中的keyword类型,和MySQL中的字段基本上差不多,当我们需要对查询字段进行精确匹配,左模糊,右模糊,全模糊,排序聚合等操作时,需要该字段的索引类型为keyword类型,否则你会发现查询没有查出想要的结果,甚至报错. 比如EE中常用的API eq(),like(),distinct()等都需要字段类型为keyword类型.
当我们需要对字段进行分词查询时,需要该字段的类型为text类型,并且指定分词器(不指定就用ES默认分词器,效果通常不理想). 比如EE中常用的API match()等都需要字段类型为text类型. 当使用match查询时未查询到预期结果时,可以先检查索引类型,然后再检查分词器,因为如果一个词没被分词器分出来,那结果也是查询不出来的.
当同一个字段,我们既需要把它当keyword类型使用,又需要把它当text类型使用时,此时我们的索引类型为keyword_text类型,EE中可以对字段添加注解@TableField(fieldType = FieldType.KEYWORD_TEXT),如此该字段就会被创建为keyword+text双类型如下图所示,值得注意的是,当我们把该字段当做keyword类型查询时,ES要求传入的字段名称为"字段名.keyword",当把该字段当text类型查询时,直接使用原字段名即可.
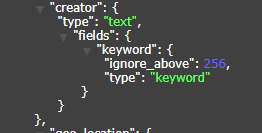
另一种做法是,可以冗余一个字段,值用相同的,一个注解标记为keyword类型,另一个标记为text类型,查询时按规则选择对应字段进行查询.
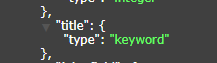
还需要注意的是,如果一个字段的索引类型被创建为仅为keyword类型(如下图所示)查询时,则不需要在其名称后面追加.keyword,直接查询就行.
3.字段id
由于框架很多功能都是借助id实现的,比如selectById,update,deleteById...,而且ES中也必须有一列作为数据id,因此我们强制要求用户封装的实体类中包含字段id列,否则框架不少功能无法正常使用.
public class Document {
/**
* es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize或直接在全局配置文件中指定,如此id便支持任意数据类型)
*/
@TableId(type = IdType.CUSTOMIZE)
private String id;
}
如果不添加@TableId注解或者添加了注解但未指定type,则id默认为es自动生成的id.
在调用insert方法时,如果该id数据在es中不存在,则新增该数据,如果已有该id数据,则即便你调用的是insert方法,实际上的效果也是更新该id对应的数据,这点需要区别于MP和MySQL.
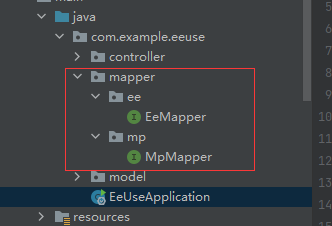
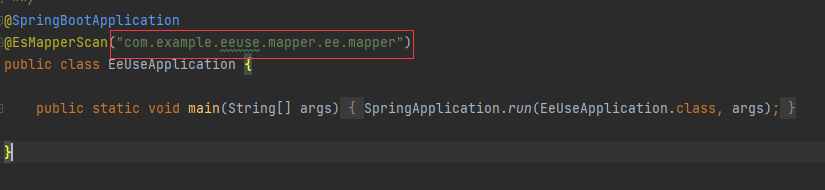
4.项目中同时使用Mybatis-Plus和Easy-Es 在此场景下,您需要将MP的mapper和EE的mapper分别放在不同的目录下,并在配置扫描路径时各自配各自的扫描路径,如此便可共存使用了,否则两者在SpringBoot启动时都去扫描同一路径,并尝试注册为自己的bean,由于底层实现依赖的类完全不一样,所以会导致其中之一注册失败,整个项目无法正常启动.可参考下图:
5.and和or的使用
需要区别于MySQL和MP,因为ES的查询参数是树形数据结构,和MySQL平铺的不一样,具体可参考and&or章节,有详细节省
关于闭坑暂时先讲这么多,后续如果有补充再追加,祝各位主公使用愉快,使用过程中有任何疑问及建议,可添加我微信252645816反馈,我们也有专门的答疑群为各位主公们免费服务.