diff --git a/CNAME b/CNAME
new file mode 100644
index 00000000..4b2a2194
--- /dev/null
+++ b/CNAME
@@ -0,0 +1 @@
+easy-es.cn
diff --git a/docs/.nojekyll b/docs/.nojekyll
new file mode 100644
index 00000000..e69de29b
diff --git a/docs/AbstractWrapper.md b/docs/AbstractWrapper.md
new file mode 100644
index 00000000..a4970bb2
--- /dev/null
+++ b/docs/AbstractWrapper.md
@@ -0,0 +1,3 @@
+> **说明:**
+> QueryWrapper(LambdaEsQueryWrapper) 和 UpdateWrapper(LambdaEsUpdateWrapper) 的父类 用于生成 语句 的 where 条件, entity 属性也用于生成 语句 的 where 条件 注意: entity 生成的 where 条件与 使用各个 api 生成的 where 条件**没有任何关联行为**
+
diff --git a/docs/CNAME b/docs/CNAME
new file mode 100644
index 00000000..4b2a2194
--- /dev/null
+++ b/docs/CNAME
@@ -0,0 +1 @@
+easy-es.cn
diff --git a/docs/QueryWrapper.md b/docs/QueryWrapper.md
new file mode 100644
index 00000000..e57c7a00
--- /dev/null
+++ b/docs/QueryWrapper.md
@@ -0,0 +1,3 @@
+> **说明:**
+> 继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件 及 LambdaEsQueryWrapper
+
diff --git a/docs/README.md b/docs/README.md
new file mode 100644
index 00000000..45ae6bba
--- /dev/null
+++ b/docs/README.md
@@ -0,0 +1,61 @@
+# 简介
+Easy-Es(简称EE)是一款基于ElasticSearch(简称Es)官方提供的RestHighLevelClient打造的低码开发框架,在 RestHighLevelClient 的基础上,只做增强不做改变,为简化开发、提高效率而生,您如果有用过Mybatis-Plus(简称MP),那么您基本可以零学习成本直接上手EE,EE是MP的Es平替版,同时也融入了更多Es独有的功能,助力您快速实现各种场景的开发.
+
+> **理念** 把简单,易用,方便留给用户,把复杂留给框架.
+
+> **愿景** 让天下没有难用的Es, 致力于成为全球最受欢迎的ElasticSearch搜索引擎开发框架.
+
+# 
+## 优势
+
+---
+
+- **屏蔽语言差异**:开发者只需要会MySQL语法即可使用Es,真正做到一通百通,无需学习枯燥易忘的Es语法,Es使用相对MySQL较低频,学了长期不用也会忘,没必要浪费这时间.开发就应该专注于业务,省下的时间去撸铁,去陪女朋友陪家人,不做资本家的韭菜
+- **代码量极少:** 与直接使用RestHighLevelClient相比,相同的查询平均可以节省3-5倍左右的代码量
+- **零魔法值:**字段名称直接从实体中获取,无需输入字段名称字符串这种魔法值,提高代码可读性,杜绝因字段名称修改而代码漏改带来的Bug
+- **零额外学习成本**:开发者只要会国内最受欢迎的Mybatis-Plus语法,即可无缝迁移至EE,EE采用和前者相同的语法,消除使用者额外学习成本,直接上手,爽
+- **降低开发者门槛: **Es通常需要中高级开发者才能驾驭,但通过接入EE,即便是只了解ES基础的初学者也可以轻松驾驭ES完成绝大多数需求的开发,可以提高人员利用率,降低企业成本
+## 特性
+
+---
+
+- **无侵入**:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
+- **损耗小**:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
+- **强大的 CRUD 操作**:内置通用 Mapper,仅仅通过少量配置即可实现大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
+- **支持 Lambda 形式调用**:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错段
+- **支持主键自动生成**:支持2 种主键策略,可自由配置,完美解决主键问题
+- **支持 ActiveRecord 模式**:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
+- **支持自定义全局通用操作**:支持全局通用方法注入( Write once, use anywhere )
+- **内置分页插件**:基于RestHighLevelClient 物理分页,开发者无需关心具体操作,且无需额外配置插件,写分页等同于普通 List 查询,且保持和PageHelper插件同样的分页返回字段,无需担心命名影响
+- **MySQL功能全覆盖**:MySQL中支持的功能通过EE都可以轻松实现
+- **支持ES高阶语法**:支持高亮搜索,分词查询,权重查询,聚合查询等高阶语法
+- **良好的拓展性**:底层仍使用RestHighLevelClient,可保持其拓展性,开发者在使用EE的同时,仍可使用RestHighLevelClient的功能
+
+...
+
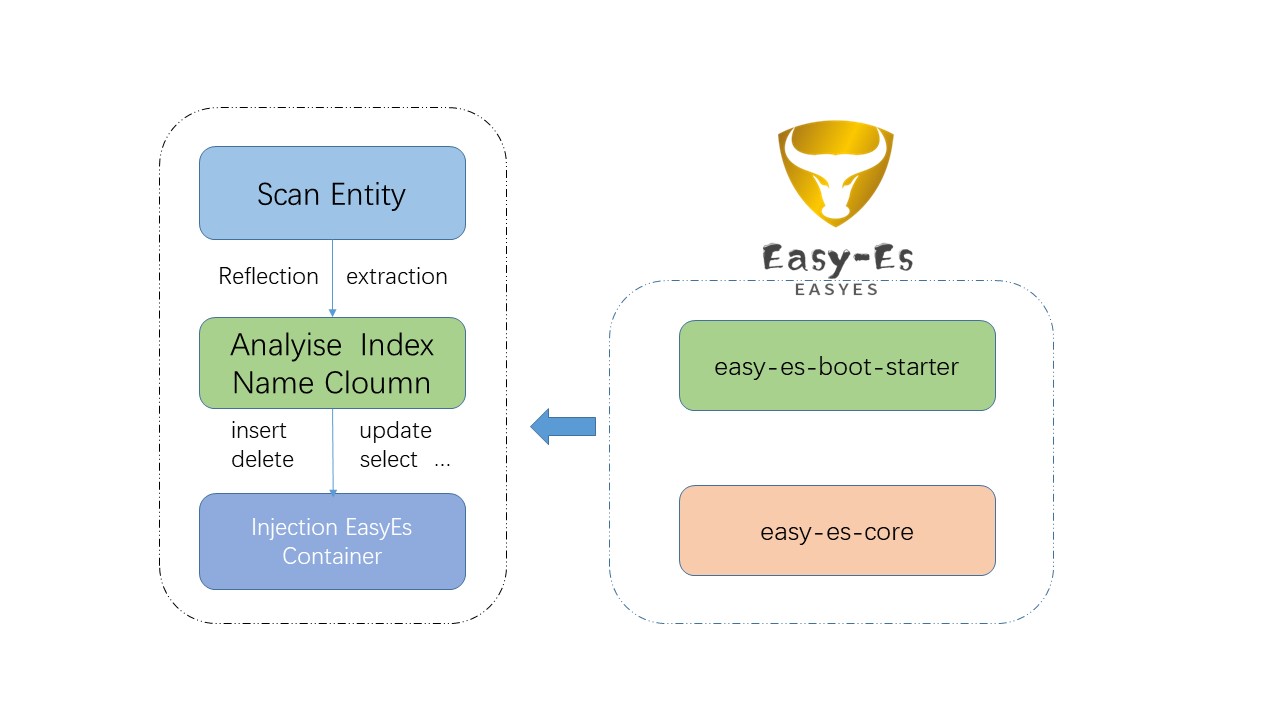
+## 框架结构
+
+---
+
+
+## 代码托管
+
+---
+
+> [码云Gitee](https://gitee.com/easy-es/easy-es)✔ | [Github](https://github.com/xpc1024/easy-es)✔
+
+## English Documentation
+
+---
+
+[Documentation-EN](https://www.yuque.com/laohan-14b9d/tald79/qf7ns2)
+
+## 参与贡献
+
+---
+
+尽管目前Easy-Es还处于新生儿状态,但由于站在巨人的肩膀上(RestHighLevelClient和Mybatis-Plus),这是一款出道即巅峰的框架,这么说并不是说它写得有多好,而是它融合了两款目前非常优秀框架的优点,这决定了它起点的高度,未来可期,所以在此欢迎各路好汉一起来参与完善 Easy-Es,我们期待你的 PR!
+
+- 贡献代码:代码地址 [Easy-ES](https://github.com/xpc1024/easy-es),欢迎提交 Issue 或者 Pull Requests
+- 维护文档:文档地址 [Easy-ES](https://www.yuque.com/laohan-14b9d/tald79/qf7ns2),欢迎参与翻译和修订
+
diff --git a/docs/UpdateWrapper.md b/docs/UpdateWrapper.md
new file mode 100644
index 00000000..204e0bf8
--- /dev/null
+++ b/docs/UpdateWrapper.md
@@ -0,0 +1,3 @@
+> **说明:**
+> 继承自 AbstractWrapper ,自身的内部属性 entity 也用于生成 where 条件 及 LambdaEsUpdateWrapper
+
diff --git a/docs/_coverpage.md b/docs/_coverpage.md
new file mode 100644
index 00000000..c077e99e
--- /dev/null
+++ b/docs/_coverpage.md
@@ -0,0 +1,9 @@
+
+
+v0.9.6
+
+本框架由 [**Gitee码云**](https://gitee.com/easy-es/easy-es) 提供金牌代码托管服务
+
+> 更易用的ES搜索引擎框架 , 为简化开发而生!
+
+[示例](demo.md)[快速开始](quick-start.md)
diff --git a/docs/_navbar.md b/docs/_navbar.md
new file mode 100644
index 00000000..ac1acddf
--- /dev/null
+++ b/docs/_navbar.md
@@ -0,0 +1,6 @@
+
+* [首页](/)
+* [联系](contact.md)
+* 语言
+ * [English](/en/)
+ * [中文](/)
\ No newline at end of file
diff --git a/docs/_sidebar.md b/docs/_sidebar.md
new file mode 100644
index 00000000..01105533
--- /dev/null
+++ b/docs/_sidebar.md
@@ -0,0 +1,79 @@
+ - [简介](README.md)
+ - [适用场景](sceen.md)
+ - [顾虑粉碎](worry-free.md)
+ - [快速开始](quick-start.md)
+ - [Springboot集成Demo](demo.md)
+ - 核心功能
+ - [index索引](index.md)
+ - [是否存在索引](exists-index.md)
+ - [删除索引](del-index.md)
+ - [更新索引](update-index.md)
+ - [创建索引](create-index.md)
+ - [索引分片](index-shard.md)
+ - [索引别名](index-alias.md)
+ - CRUD接口
+ - [Select](select.md)
+ - [Update](update.md)
+ - [Delete](delete.md)
+ - [Insert](insert.md)
+ - [条件构造器](condition.md)
+ - [eq](eq.md)
+ - [ne](ne.md)
+ - [match](match.md)
+ - [gt](gt.md)
+ - [ge](ge.md)
+ - [lt](lt.md)
+ - [le](le.md)
+ - [between](between.md)
+ - [notBetween](notBetween.md)
+ - [like](like.md)
+ - [notLike](notLike.md)
+ - [likeLeft](likeLeft.md)
+ - [likeRight](likeRight.md)
+ - [isNull](isNull.md)
+ - [isNotNull](isNotNull.md)
+ - [in](in.md)
+ - [notIn](notIn.md)
+ - [groupBy](groupBy.md)
+ - [orderByAsc](orderByAsc.md)
+ - [orderByDesc](orderByDesc.md)
+ - [or](or.md)
+ - [and](and.md)
+ - [limit](limit.md)
+ - [from](from.md)
+ - [size](size.md)
+ - [set](set.md)
+ - [AbstractWrapper](AbstractWrapper.md)
+ - [QueryWrapper](QueryWrapper.md)
+ - [UpdateWrapper](UpdateWrapper.md)
+ - 拓展功能
+ - [混合查询](hybrid-query.md)
+ - [原生查询](origin-query.md)
+ - [source](source.md)
+ - [分页](page.md)
+ - 高阶语法
+ - [字段过滤](filter.md)
+ - [排序](sort.md)
+ - [聚合查询](aggregation.md)
+ - [分词查询](particple.md)
+ - [权重](weight.md)
+ - [高亮查询](highlight.md)
+ - [GEO地理位置查询](geo.md)
+ - [GeoBoundingBox](geo-bounding-box.md)
+ - [GeoDistance](geo-distance.md)
+ - [GeoPolygon](geo-ploygon.md)
+ - [GeoShape](geo-shape.md)
+ - 注解
+ - [索引注解](index-anno.md)
+ - [字段注解](field-anno.md)
+ - [主键注解](id-anno.md)
+ - [配置](config.md)
+ - [更新计划](update-plan.md)
+ - [更新日志](update-log.md)
+ - [FAQ](faq.md)
+ - [与MP差异](diff.md)
+ - [MySQL与Easy-Es语法对照表](compare.md)
+ - [捐赠支持](donate.md)
+ - [捐赠记录](donate-log.md)
+ - [版权](copyright.md)
+ - [鸣谢](thanks.md)
\ No newline at end of file
diff --git a/docs/aggregation.md b/docs/aggregation.md
new file mode 100644
index 00000000..21f77465
--- /dev/null
+++ b/docs/aggregation.md
@@ -0,0 +1,28 @@
+在MySQL中,我们可以通过指定字段进行group by聚合,EE同样也支持聚合:
+```java
+ @Test
+ public void testGroupBy() throws IOException {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.likeRight(Document::getContent,"推");
+ wrapper.groupBy(Document::getCreator);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> **Tips:**
+> 尽管语法与MP一致,但实际上,ES的聚合结果是放在单独的对象中的,格式如下所示,因此我们高阶语法均需要用SearchResponse来接收返回结果,这点需要区别于MP和MySQL.
+
+```json
+"aggregations":{"sterms#creator":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"老汉","doc_count":2},{"key":"老王","doc_count":1}]}}
+```
+其它聚合:
+```json
+// 求最小值
+wrapper.min();
+// 求最大值
+wrapper.max();
+// 求平均值
+wrapper.avg();
+// 求和
+wrapper.sum();
+```
diff --git a/docs/and.md b/docs/and.md
new file mode 100644
index 00000000..64838660
--- /dev/null
+++ b/docs/and.md
@@ -0,0 +1,7 @@
+```java
+and(Consumer consumer)
+and(boolean condition, Consumer consumer)
+```
+
+- AND 嵌套
+- 例: and(i -> i.eq(Document::getTitle, "Hello").ne(Document::getCreator, "Guy"))--->and (title ='Hello' and creator != 'Guy' )
diff --git a/docs/between.md b/docs/between.md
new file mode 100644
index 00000000..45b772ef
--- /dev/null
+++ b/docs/between.md
@@ -0,0 +1,7 @@
+```java
+between(R column, Object val1, Object val2)
+between(boolean condition, R column, Object val1, Object val2)
+```
+
+- BETWEEN 值1 AND 值2
+- 例: between("age", 18, 30)--->age between 18 and 30
diff --git a/docs/compare.md b/docs/compare.md
new file mode 100644
index 00000000..41b07405
--- /dev/null
+++ b/docs/compare.md
@@ -0,0 +1,33 @@
+| MySQL | Easy-Es |
+| --- | --- |
+| and | and |
+| or | or |
+| = | eq |
+| != | ne |
+| > | gt |
+| >= | ge |
+| < | lt |
+| <= | le |
+| like '%field%' | like |
+| not like '%field%' | notLike |
+| like '%field' | likeLeft |
+| like 'field%' | likeRight |
+| between | between |
+| notBetween | notBetween |
+| is null | isNull |
+| is notNull | isNotNull |
+| in | in |
+| not in | notIn |
+| group by | groupBy |
+| order by | orderBy |
+| min | min |
+| max | max |
+| avg | avg |
+| sum | sum |
+| sum | sum |
+| - | orderByAsc |
+| - | orderByDesc |
+| - | match |
+| - | highLight |
+| ... | ... |
+
diff --git a/docs/condition.md b/docs/condition.md
new file mode 100644
index 00000000..a6f179b5
--- /dev/null
+++ b/docs/condition.md
@@ -0,0 +1,17 @@
+> **说明:**
+> - 以下出现的第一个入参boolean condition表示该条件是否加入最后生成的语句中,例如:query.like(StringUtils.isNotBlank(name), Entity::getName, name) .eq(age!=null && age >= 0, Entity::getAge, age)
+> - 以下代码块内的多个方法均为从上往下补全个别boolean类型的入参,默认为true
+> - 以下出现的泛型Param均为Wrapper的子类实例(均具有AbstractWrapper的所有方法)
+> - 以下方法在入参中出现的R为泛型,在普通wrapper中是String,在LambdaWrapper中是函数(例:Entity::getId,Entity为实体类,getId为字段id的getMethod)
+> - 以下方法入参中的R column均表示数据库字段,当R具体类型为String时则为数据库字段名(字段名是数据库关键字的自己用转义符包裹!)!而不是实体类数据字段名!!!,另当R具体类型为SFunction时项目runtime不支持eclipse自家的编译器!!!
+> - 以下举例均为使用普通wrapper,入参为Map和List的均以json形式表现!
+> - 使用中如果入参的Map或者List为空,则不会加入最后生成的sql中!
+> - 有任何疑问就点开源码看,看不懂函数的[点击我学习新知识](https://www.jianshu.com/p/613a6118e2e0)
+
+> **警告:**
+> 不支持以及不赞成在 RPC 调用中把 Wrapper 进行传输
+> 1. wrapper 很重
+> 1. 传输 wrapper 可以类比为你的 controller 用 map 接收值(开发一时爽,维护火葬场)
+> 1. 正确的 RPC 调用姿势是写一个 DTO 进行传输,被调用方再根据 DTO 执行相应的操作
+> 1. 我们拒绝接受任何关于 RPC 传输 Wrapper 报错相关的 issue 甚至 pr
+
diff --git a/docs/config.md b/docs/config.md
new file mode 100644
index 00000000..836f9423
--- /dev/null
+++ b/docs/config.md
@@ -0,0 +1,43 @@
+**基础配置:** 如果缺失可导致项目无法正常启动,其中账号密码可缺省.
+```yaml
+easy-es:
+ enable: true # 是否开启EE自动配置
+ address : 127.0.0.1:9200 # es连接地址+端口 格式必须为ip:port,如果是集群则可用逗号隔开
+ schema: http # 默认为http
+ username: elastic #如果无账号密码则可不配置此行
+ password: WG7WVmuNMtM4GwNYkyWH #如果无账号密码则可不配置此行
+```
+**拓展配置:** 可缺省,为了提高生产性能,你可以进一步配置(0.9.4+版本才支持)
+```yaml
+easy-es:
+ connectTimeout: 5000 # 连接超时时间 单位:ms
+ socketTimeout: 5000 # 通信超时时间 单位:ms
+ requestTimeout: 5000 # 请求超时时间 单位:ms
+ connectionRequestTimeout: 5000 # 连接请求超时时间 单位:ms
+ maxConnTotal: 100 # 最大连接数 单位:个
+ maxConnPerRoute: 100 # 最大连接路由数 单位:个
+```
+**全局配置:** 可缺省,不影响项目启动,若缺省则为默认值
+```yaml
+easy-es:
+ global-config:
+ db-config:
+ table-prefix: daily_ # 索引前缀,可用于区分环境 默认为空
+ id-type: auto # id生成策略 默认为auto
+ field-strategy: not_empty # 字段更新策略 默认为not_null
+
+```
+> **Tips:**
+> - id-type支持2种类型:
+>
+ auto: 由ES自动生成,是默认的配置,无需您额外配置 推荐
+> uuid: 系统生成UUID,然后插入ES (不推荐)
+> - field-strategy支持3种类型:
+>
+ not_null: 非Null判断,字段值为非Null时,才会被更新
+> not_empty: 非空判断,字段值为非空字符串时才会被更新
+> ignore: 忽略判断,无论字段值为什么,都会被更新
+> - 在配置了全局策略后,您仍可以通过注解针对个别类进行个性化配置,全局配置的优先级是小于注解配置的
+
+>
+
diff --git a/docs/contact.md b/docs/contact.md
new file mode 100644
index 00000000..f3c7043c
--- /dev/null
+++ b/docs/contact.md
@@ -0,0 +1,15 @@
+坐标:杭州
+
+开发5年全栈菜狗,健身8年肌肉猛男,欢迎臭味相投的朋友来撩.
+
+如您也对开源感兴趣,欢迎加入我们技术团队,诚邀全球各路豪杰,群策群力,打造更好的开源项目.
+
+目前有家淘宝金牌店铺,健身补剂专卖,食品行业营业证照齐全,供应链稳定,但苦于无太多时间经营,未来有计划重振,也招募有志之士一起合作,配有一套本人开源的[健身计划一键生成系统](https://gitee.com/easy-es/fit-plan),可用于给客户提供免费的健身计划.
+
+QQ|微信 (同号) : 252645816
+
+技术&健身讨论群: 247637156
+
+微信群因无群号且动态码,如需进微信群的朋友须先添加本人微信,由本人拉入.
+
+个人技术博客:[CSDN博客](https://blog.csdn.net/lovexiaotaozi)
diff --git a/docs/copyright.md b/docs/copyright.md
new file mode 100644
index 00000000..ef1a3772
--- /dev/null
+++ b/docs/copyright.md
@@ -0,0 +1,5 @@
+本框架为了保持与MP一致的语法,有部分代码来源于开源框架[Mybatis-Plus](https://mp.baomidou.com/),或是对其做了修改,在此特别声明.
+
+本框架底层使用了ElasticSearch官方开源框架[RestHighLevelClient](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html),在此特别声明.
+
+本框架采用和Mybatis-plus一样的[Apache2.0开源协议](https://www.apache.org/licenses/LICENSE-2.0),并且承诺永不参与商业用途,仅供大家无偿使用.
diff --git a/docs/create-index.md b/docs/create-index.md
new file mode 100644
index 00000000..68440b58
--- /dev/null
+++ b/docs/create-index.md
@@ -0,0 +1,27 @@
+```java
+ @Test
+ public void testCreatIndex() {
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+ // 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
+ wrapper.indexName(Document.class.getSimpleName().toLowerCase());
+
+ // 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型,可缺省
+ // 支持分词查询,内容分词器可指定,查询分词器也可指定,,均可缺省或只指定其中之一,不指定则为ES默认分词器(standard)
+ wrapper.mapping(Document::getTitle, FieldType.KEYWORD)
+ .mapping(Document::getContent, FieldType.TEXT,Analyzer.IK_MAX_WORD,Analyzer.IK_MAX_WORD);
+
+ // 设置分片及副本信息,3个shards,2个replicas,可缺省
+ wrapper.settings(3,2);
+
+ // 设置别名信息,可缺省
+ String aliasName = "daily";
+ wrapper.createAlias(aliasName);
+
+ // 创建索引
+ boolean isOk = documentMapper.createIndex(wrapper);
+ Assert.assertTrue(isOk);
+ }
+```
+> **Tips:**
+> 由于ES索引改动自动重建的特性,因此本接口设计时将创建索引所需的mapping,settings,alias信息三合一了,尽管其中每一项配置都可缺省,但我们仍建议您在创建索引前提前规划好以上信息,可以规避后续修改带来的不必要麻烦,若后续确有修改,您仍可以通过别名迁移的方式(推荐,可平滑过渡),或删除原索引重新创建的方式进行修改.
+
diff --git a/docs/create_index.md b/docs/create_index.md
new file mode 100644
index 00000000..43cf8e37
--- /dev/null
+++ b/docs/create_index.md
@@ -0,0 +1 @@
+create_index.md
\ No newline at end of file
diff --git a/docs/del-index.md b/docs/del-index.md
new file mode 100644
index 00000000..00ae3c7b
--- /dev/null
+++ b/docs/del-index.md
@@ -0,0 +1,12 @@
+> 删除索引,生产环境请谨慎操作,恢复代价和难度高
+
+```java
+ @Test
+ public void testDeleteIndex(){
+ // 测试删除索引
+ // 指定要删除哪个索引
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ boolean isOk = documentMapper.deleteIndex(indexName);
+ Assert.assertTrue(isOk);
+ }
+```
diff --git a/docs/del_index.md b/docs/del_index.md
new file mode 100644
index 00000000..e69de29b
diff --git a/docs/delete.md b/docs/delete.md
new file mode 100644
index 00000000..885522d2
--- /dev/null
+++ b/docs/delete.md
@@ -0,0 +1,17 @@
+```java
+ // 根据 ID 删除
+Integer deleteById(Serializable id);
+
+// 根据 entity 条件,删除记录
+Integer delete(LambdaEsQueryWrapper wrapper);
+
+// 删除(根据ID 批量删除)
+Integer deleteBatchIds(Collection idList);
+```
+##### 参数说明
+| 类型 | 参数名 | 描述 |
+| --- | --- | --- |
+| Wrapper | queryWrapper | 实体包装类 QueryWrapper |
+| Serializable | id | 主键ID |
+| Collection | idList | 主键ID列表 |
+
diff --git a/docs/deleted.md b/docs/deleted.md
new file mode 100644
index 00000000..e69de29b
diff --git a/docs/demo.md b/docs/demo.md
new file mode 100644
index 00000000..46038e08
--- /dev/null
+++ b/docs/demo.md
@@ -0,0 +1,144 @@
+> 本Demo演示Easy-Es与Springboot项目无缝集成,建议先下载,可直接在您本地运行.
+> Demo下载地址: ✔[Gitee](https://gitee.com/easy-es/easy-es-springboot-demo) | ✔ [Github](https://github.com/xpc1024/easy-es-springboot-demo)
+
+# Demo介绍
+
+---
+
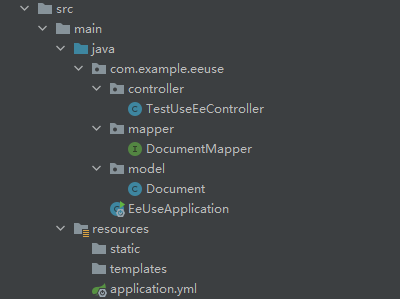
+## 1.项目结构
+
+---
+
+
+
+ 为了演示方便,本demo省略service层
+
+## 2.Pom
+
+---
+
+```xml
+
+
+ 4.0.0
+
+ org.springframework.boot
+ spring-boot-starter-parent
+ 2.6.0
+
+
+ com.example
+ ee-use
+ 0.0.1-SNAPSHOT
+ ee-use
+ Demo project for Spring Boot
+
+ 1.8
+
+
+
+ org.springframework.boot
+ spring-boot-starter-web
+
+
+
+ io.github.xpc1024
+ easy-es-boot-starter
+ 0.9.6
+
+
+
+ org.springframework.boot
+ spring-boot-starter-test
+ test
+
+
+
+
+
+
+ org.springframework.boot
+ spring-boot-maven-plugin
+
+
+
+
+
+
+```
+
+## 3.核心代码
+
+---
+
+```java
+@RestController
+@RequiredArgsConstructor(onConstructor = @__(@Autowired))
+public class TestUseEeController {
+ private final DocumentMapper documentMapper;
+
+ @GetMapping("/index")
+ public Boolean index() {
+ // 初始化-> 创建索引,相当于MySQL建表 | 此接口须首先调用,只调用一次即可
+ LambdaEsIndexWrapper indexWrapper = new LambdaEsIndexWrapper<>();
+ indexWrapper.indexName(Document.class.getSimpleName().toLowerCase());
+ indexWrapper.mapping(Document::getTitle, FieldType.KEYWORD)
+ .mapping(Document::getContent, FieldType.TEXT);
+ documentMapper.createIndex(indexWrapper);
+ return Boolean.TRUE;
+ }
+
+ @GetMapping("/insert")
+ public Integer insert() {
+ // 初始化-> 新增数据
+ Document document = new Document();
+ document.setTitle("老汉");
+ document.setContent("推*技术过硬");
+ return documentMapper.insert(document);
+ }
+
+ @GetMapping("/search")
+ public List search() {
+ // 查询出所有标题为老汉的文档列表
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.eq(Document::getTitle, "老汉");
+ return documentMapper.selectList(wrapper);
+ }
+}
+```
+
+## 4.启动及使用
+
+---
+
+### a.添加配置信息
+```yaml
+easy-es:
+ enable: true # 默认为true,若为false时,则认为不启用本框架
+ address : 127.0.0.0:9200 #填你的es连接地址
+ # username: 有设置才填写,非必须
+ # password: 有设置才填写,非必须
+```
+### b.启动项目
+使用你的IDE启动项目
+
+
+
+### c.使用
+依次在浏览器访问 [http://localhost:8080/index](http://localhost:8080/index) (仅访问一次即可,完成索引创建,相当于MySQL建表,有了表才能进行后续CRUD)
+
+[http://localhost:8080/insert](http://localhost:8080/insert) (插入数据)
+
+[http://localhost:8080/search](http://localhost:8080/search) (查询)
+
+效果图:
+
+
+
+
+## 5.结语
+
+---
+
+至此,您已初步体验Easy-Es的基本功能,如果你感觉使用起来体验还不错,想进一步体验更多强大功能,那就继续往下看吧!
diff --git a/docs/diff.md b/docs/diff.md
new file mode 100644
index 00000000..da17dc3b
--- /dev/null
+++ b/docs/diff.md
@@ -0,0 +1,68 @@
+> 为了减少开发者的额外学习负担,我们尽量保持了和MP几乎一致的语法,但为了避免歧义,仍有个别地方存在些许差异,无论如何,在你看完这些差异和原因后,你肯定也会赞同这种差异存在的必要性.
+
+
+**1.命名差异** 为了区别MP的命名带来的歧义问题,以下三处命名中我们加了Es字母区别于MP:
+
+| | MP | EE | 差异原因 |
+| --- | --- | --- | --- |
+| 启动类注解 | @MapperScan("xxx") | @EsMapperScan("xxx") | 一个项目中可能会同时用到MP和EE,避免同一系统中同时引入同名注解时,需要加全路径区分 |
+| 父类Mapper命名 | BaseMapper | BaseEsMapper | 一个项目中可能会同时用到MP和EE,避免继承时误继承到MP的Mapper |
+| 条件构造器命名 | LambdaQueryWrapper | LambdaEsQueryWrapper | 一个项目中可能会同时用到MP和EE,避免错误创建条件构造器 |
+
+**2.移除了Service** MP中引入了Service层,但EE中并无Service层,因为我个人认为MP的Service层太重了,不够灵活,实际开发中基本不用,被很多人吐槽,所以EE中我直接去掉了Service层,在使用过程中你无需像MP那样继承ISevice,另外我把一些高频使用的service层封装的方法下沉到了mapper层,比如批量更新,批量新增等,大家可以在调用基类Mapper层中的方法时看到,灵活且不失优雅.
+
+**3.方法差异** ▼ group by 聚合 在EE中使用groupBy方法时,调用查询接口必须使用获取原生返回内容,不能像MP中一样返回泛型T,这点是由于ES和MySQL的差导致的,所以需要特别注意
+```java
+
+LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
+wrapper.groupBy(T::getField);
+
+// MP语法
+List list = xxxMapper.selectList(wrapper);
+// EE语法
+SearchResponse response = xxxMapper.search(wrapper);
+```
+因为Es会把聚合的结果单独放到aggregations对象中,但原来的实体对象中并无此字段,所以我们需要用SearchResponse接收查询返回的结果,我们所需要的所有查询信息都可以从SearchResponse中获取.
+```json
+"aggregations":{"sterms#creator":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"老汉","doc_count":2},{"key":"老王","doc_count":1}]}}
+```
+
+移除了几个低频且不符合编码规范的方法:
+```
+allEq(Map params)
+allEq(Map params, boolean null2IsNull)
+allEq(boolean condition, Map params, boolean null2IsNull)
+```
+你完全可以用eq()方法代替上述方法,可以避免代码中出现魔法值. 移除了几个我目前还没看到使用场景的方法:
+```
+having(String sqlHaving, Object... params)
+having(boolean condition, String sqlHaving, Object... params)
+func(Consumer consumer)
+func(boolean condition, Consumer consumer)
+```
+新增了一些EE有但MP不支持的方法:
+```
+// 索引创建相关
+Boolean existsIndex(String indexName);
+Boolean createIndex(LambdaEsIndexWrapper wrapper);
+Boolean updateIndex(LambdaEsIndexWrapper wrapper);
+Boolean deleteIndex(String indexName);
+
+// 高亮
+highLight(高亮字段);
+highLight(高亮字段,开始标签,结束标签)
+
+// 权重
+function(字段, 值, Float 权重值)
+
+// Geo 地理位置相关
+geoBoundingBox(R column, GeoPoint topLeft, GeoPoint bottomRight);
+geoDistance(R column, Double distance, DistanceUnit distanceUnit, GeoPoint centralGeoPoint);
+geoPolygon(R column, List geoPoints)geoShape(R column, String indexedShapeId);
+geoShape(R column, String indexedShapeId);
+geoShape(R column, Geometry geometry, ShapeRelation shapeRelation);
+
+```
+**4.功能阉割** 在全局配置,自定义注解上EE支持的功能没有MP那么多,但是已经支持的那些功能用起来与MP一样,目前已经支持了MP中常用的功能,以及高频功能,低频的后续的迭代中也会陆续跟上MP的脚步,尽量做到全支持.
+
+除了需要注意以上列出的这些小差异,其余地方和MP并无差异,使用者完全可以像使用MP一样使用EE
diff --git a/docs/donate-log.md b/docs/donate-log.md
new file mode 100644
index 00000000..280d39e9
--- /dev/null
+++ b/docs/donate-log.md
@@ -0,0 +1,17 @@
+2021年12月---感谢作者本人为此框架捐赠0.1元,打破了无人捐款的囧境!
+
+2022年1月---感谢CJ捐赠5元,算是真正意义上的首捐,虽然金额不大,但非常感谢这份支持,极大提振了开发者信心
+
+2022年1月---感谢橘子皮先生捐赠6.66元
+
+2022年2月 --- 感谢做好事不留名的 *y 网友捐赠50元请作者喝咖啡
+
+2022年3月--- 感谢chenzf捐赠1元 是码云上的首捐
+
+2022年3月 --- 感谢以梦为马,不负韶华先生捐赠50元
+
+2022年3月 --- 感谢璐先生为本系统官网捐赠服务器
+
+...
+
+感谢以上所有捐赠,感谢大家对开源开发者的肯定和支持,此举也在推动全球开源事业发展,功德无量!
diff --git a/docs/donate.md b/docs/donate.md
new file mode 100644
index 00000000..e45904f1
--- /dev/null
+++ b/docs/donate.md
@@ -0,0 +1,14 @@
+> 您的支持是鼓励我们前行的动力,无论金额多少都足够表达您这份心意。
+
+
+
+
+
+
+
+捐赠途径: 由于新的政策走向,未来二维码可能无法收款,您亦可通过[Gitee码云平台](https://gitee.com/easy-es/easy-es)本仓库右下角捐赠按钮直接捐赠.
+
+捐赠请备注,我们会将您的捐赠信息上传至本页面,每一份捐赠可根据您的意愿决定是否公示(默认公示).
+
+捐赠形式金额不限,甚至可以捐赠服务器,域名,SSL证书等,每一份捐赠都是对全球开源事业的支持,谢谢您!
+
diff --git a/docs/en/.nojekyll b/docs/en/.nojekyll
new file mode 100644
index 00000000..e69de29b
diff --git a/docs/en/AbstractWrapper.md b/docs/en/AbstractWrapper.md
new file mode 100644
index 00000000..9d93b809
--- /dev/null
+++ b/docs/en/AbstractWrapper.md
@@ -0,0 +1,5 @@
+> **Instruction:**
+> The parent class of QueryWrapper(LambdaEsQueryWrapper) and UpdateWrapper(LambdaEsUpdateWrapper)
+> Used to generate the where condition of the statement, and the entity attribute is also used to generate the where condition of the statement
+> Note: The where condition generated by the entity has no associated behavior with the where condition generated by each api
+
diff --git a/docs/en/Annotation.md b/docs/en/Annotation.md
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ b/docs/en/Annotation.md
@@ -0,0 +1 @@
+
diff --git a/docs/en/CNAME b/docs/en/CNAME
new file mode 100644
index 00000000..1d729efb
--- /dev/null
+++ b/docs/en/CNAME
@@ -0,0 +1 @@
+easy-es.cn
\ No newline at end of file
diff --git a/docs/en/Expand Function.md b/docs/en/Expand Function.md
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ b/docs/en/Expand Function.md
@@ -0,0 +1 @@
+
diff --git a/docs/en/High-level grammar.md b/docs/en/High-level grammar.md
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ b/docs/en/High-level grammar.md
@@ -0,0 +1 @@
+
diff --git a/docs/en/QueryWrapper.md b/docs/en/QueryWrapper.md
new file mode 100644
index 00000000..13033f21
--- /dev/null
+++ b/docs/en/QueryWrapper.md
@@ -0,0 +1,4 @@
+> **Instruction:**
+> Inherited from AbstractWrapper, its own internal attribute entity is also used to generate where conditions
+> And LambdaEsQueryWrapper
+
diff --git a/docs/en/README.md b/docs/en/README.md
new file mode 100644
index 00000000..15da1627
--- /dev/null
+++ b/docs/en/README.md
@@ -0,0 +1,42 @@
+# Introduction
+
+---
+
+Easy-Es (EE for short) is a low-code development framework based on RestHighLevelClient officially provided by ElasticSearch (Es for short). If you have used Mybatis-Plus (MP for short), then you can basically get started with EE at zero learning cost. EE is an Es replacement version of MP, and it also incorporates more unique functions of Es to help you quickly realize various scenarios. development.
+
+> **Philosophy:** Leave simplicity, ease of use, and convenience to users, and leave complexity to the framework.
+
+
+> **Vision:** Let the world have no difficult Es, and strive to become the world's most popular ElasticSearch search engine development framework.
+
+
+
+## Advantage
+
+---
+
+- **Block language differences:** Developers only need to know MySQL syntax to use Es.
+- **Low code:** Compared with using RestHighLevelClient, the same query can save about 3-5 times the amount of code on average.
+- **Easier to get field names:** The field name is obtained directly from the entity, no need to enter the field name string, which improves the readability of the code and eliminates the bugs caused by the omission of the code due to the modification of the field name.
+- **Lower the barriers for developers:** Even beginners who only understand the basics of ES can easily control ES.
+
+## Architecture
+
+---
+
+
+
+## Code hosting
+
+---
+
+> [Gitee](https://gitee.com/easy-es/easy-es)✔ 丨 [Github](https://github.com/xpc1024/easy-es)✔
+
+## Participate in contribution
+
+---
+
+We welcome all developers to participate in the improvement of Easy-Es, and we look forward to your contribution.
+
+- **Contribution code:** code address [Easy-ES](https://github.com/xpc1024/easy-es), welcome to submit Issue or Pull Requests
+- **Document maintenance:** Document address [Easy-ES](https://www.yuque.com/laohan-14b9d/tald79/qf7ns2), welcome to participate in translation and revision
diff --git a/docs/en/UpdateWrapper.md b/docs/en/UpdateWrapper.md
new file mode 100644
index 00000000..3b298b1c
--- /dev/null
+++ b/docs/en/UpdateWrapper.md
@@ -0,0 +1,4 @@
+> **Instruction:**
+> Inherited from AbstractWrapper, its own internal attribute entity is also used to generate where conditions
+> And LambdaEsUpdateWrapper
+
diff --git a/docs/en/_coverpage.md b/docs/en/_coverpage.md
new file mode 100644
index 00000000..a36eccda
--- /dev/null
+++ b/docs/en/_coverpage.md
@@ -0,0 +1,10 @@
+
+
+v0.9.6
+
+This framework is provided by [**Gitee**](https://gitee.com/easy-es/easy-es) with high-quality code hosting services
+
+> An easier-to-use ES search engine framework, born to simplify development!
+
+
+[Example](/en/demo.md)[Getting started](/en/quick-start.md)
diff --git a/docs/en/_navbar.md b/docs/en/_navbar.md
new file mode 100644
index 00000000..1792e048
--- /dev/null
+++ b/docs/en/_navbar.md
@@ -0,0 +1,6 @@
+
+* [Home](/en/)
+* [Contact](/en/contact.md)
+* Lang
+ * [English](/en/)
+ * [中文](/)
\ No newline at end of file
diff --git a/docs/en/_sidebar.md b/docs/en/_sidebar.md
new file mode 100644
index 00000000..cce9b1b2
--- /dev/null
+++ b/docs/en/_sidebar.md
@@ -0,0 +1,75 @@
+ - [Introduction](/en/README.md)
+ - [Applicable scene](/en/sceen.md)
+ - [Worry-free](/en/worry-free.md)
+ - [Quick start](/en/quick-start.md)
+ - [Springboot integration demo](/en/demo.md)
+ - Core Function
+ - [index](/en/index.md)
+ - [exists index](/en/exists-index.md)
+ - [delete index](/en/del-index.md)
+ - [update index](/en/update-index.md)
+ - [create index](/en/create-index.md)
+ - [index shard](/en/index-shard.md)
+ - [index alias](/en/index-alias.md)
+ - CRUD Interfaces
+ - [Select](/en/select.md)
+ - [Update](/en/update.md)
+ - [Delete](/en/delete.md)
+ - [Insert](/en/insert.md)
+ - [Conditional Constructor](/en/condition.md)
+ - [eq](/en/eq.md)
+ - [ne](/en/ne.md)
+ - [match](/en/match.md)
+ - [gt](/en/gt.md)
+ - [ge](/en/ge.md)
+ - [lt](/en/lt.md)
+ - [le](/en/le.md)
+ - [between](/en/between.md)
+ - [notBetween](/en/notBetween.md)
+ - [like](/en/like.md)
+ - [notLike](/en/notLike.md)
+ - [likeLeft](/en/likeLeft.md)
+ - [likeRight](/en/likeRight.md)
+ - [isNull](/en/isNull.md)
+ - [isNotNull](/en/isNotNull.md)
+ - [in](/en/in.md)
+ - [notIn](/en/notIn.md)
+ - [groupBy](/en/groupBy.md)
+ - [orderByAsc](/en/orderByAsc.md)
+ - [orderByDesc](/en/orderByDesc.md)
+ - [or](/en/or.md)
+ - [and](/en/and.md)
+ - [limit](/en/limit.md)
+ - [from](/en/from.md)
+ - [size](/en/size.md)
+ - [set](/en/set.md)
+ - [AbstractWrapper](/en/AbstractWrapper.md)
+ - [QueryWrapper](/en/QueryWrapper.md)
+ - [UpdateWrapper](/en/UpdateWrapper.md)
+ - Expand Fucntion
+ - [Hybrid query](/en/hybrid-query.md)
+ - [Es Native query](/en/origin-query.md)
+ - [source](/en/source.md)
+ - [pagination](/en/page.md)
+ - High-level grammar
+ - [Field Filtering](/en/filter.md)
+ - [Sort](/en/sort.md)
+ - [Aggregate query](/en/aggregation.md)
+ - [Word segmentation query](/en/particple.md)
+ - [Weight](/en/weight.md)
+ - [Highlight query](/en/highlight.md)
+ - [GEO query](/en/geo.md)
+ - [GeoBoundingBox](/en/geo-bounding-box.md)
+ - [GeoDistance](/en/geo-distance.md)
+ - [GeoPolygon](/en/geo-polygon.md)
+ - [GeoShape](/en/geo-shape.md)
+ - Annotation
+ - [Index annotation](/en/index-anno.md)
+ - [Field annotation](/en/field-anno.md)
+ - [Primary key annotation](/en/id-anno.md)
+ - [configuration](/en/config.md)
+ - [FAQ](/en/faq.md)
+ - [Difference between EE and MySQL syntax](/en/compare.md)
+ - [Donate](/en/donate.md)
+ - [Copyright](/en/copyright.md)
+
\ No newline at end of file
diff --git a/docs/en/aggregation.md b/docs/en/aggregation.md
new file mode 100644
index 00000000..7d480964
--- /dev/null
+++ b/docs/en/aggregation.md
@@ -0,0 +1,25 @@
+> In MySQL, we can perform group by aggregation by specifying fields, and EE also supports aggregation:
+
+```java
+ @Test
+ public void testGroupBy() throws IOException {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.like(Document::getContent,"world");
+ wrapper.groupBy(Document::getCreator);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> **Tips:**
+> The aggregation result of Es is placed in a separate object, so we need to use a semi-native query method to return SearchResponse to get the aggregation result
+
+Other aggregations:
+```java
+// Find the minimum
+wrapper.min();
+// Find the maximum
+wrapper.max();
+// average
+wrapper.avg();
+wrapper.sum();
+```
diff --git a/docs/en/and.md b/docs/en/and.md
new file mode 100644
index 00000000..4517ccdd
--- /dev/null
+++ b/docs/en/and.md
@@ -0,0 +1,5 @@
+```java
+and(Consumer consumer)
+and(boolean condition, Consumer consumer)
+```
+● AND nesting ● Example: and(i -> i.eq(Document::getTitle, "Hello").ne(Document::getCreator, "Guy"))--->and (title ='Hello' and creator != 'Guy' )
diff --git a/docs/en/between.md b/docs/en/between.md
new file mode 100644
index 00000000..8d1bbed0
--- /dev/null
+++ b/docs/en/between.md
@@ -0,0 +1,5 @@
+```java
+between(R column, Object val1, Object val2)
+between(boolean condition, R column, Object val1, Object val2)
+```
+● BETWEEN value 1 AND value 2 ● Example: between("age", 18, 30)--->age between 18 and 30
diff --git a/docs/en/compare.md b/docs/en/compare.md
new file mode 100644
index 00000000..6c17369f
--- /dev/null
+++ b/docs/en/compare.md
@@ -0,0 +1,35 @@
+| MySQL | Easy-Es |
+| --- | --- |
+| and | and |
+| or | or |
+| = | eq |
+| != | ne |
+| > | gt |
+| >= | ge |
+| < | lt |
+| <= | le |
+| like '%field%' | like |
+| not like '%field%' | notLike |
+| like '%field' | likeLeft |
+| like 'field%' | likeRight |
+| between | between |
+| notBetween | notBetween |
+| is null | isNull |
+| is notNull | isNotNull |
+| in | in |
+| not in | notIn |
+| group by | groupBy |
+| order by | orderBy |
+| min | min |
+| max | max |
+| avg | avg |
+| sum | sum |
+| sum | sum |
+| - | orderByAsc |
+| - | orderByDesc |
+| - | match |
+| - | highLight |
+| ... | ... |
+
+
+
diff --git a/docs/en/condition.md b/docs/en/condition.md
new file mode 100644
index 00000000..06bbba5f
--- /dev/null
+++ b/docs/en/condition.md
@@ -0,0 +1,17 @@
+> **Instruction:**
+> - The first input parameter boolean condition that appears below indicates whether the condition is added to the last generated statement, for example: query.like(StringUtils.isNotBlank(name), Entity::getName, name) .eq(age!=null && age >= 0, Entity::getAge, age)
+> - The multiple methods in the following code block are all input parameters of individual boolean types from top to bottom, and the default is true
+> - The generic Param appearing below are all subclass instances of Wrapper (all have all the methods of AbstractWrapper)
+> - The R that appears in the input parameters of the following methods is generic, String in ordinary wrapper, and function in LambdaWrapper (example: Entity::getId, Entity is the entity class, getId is the getMethod of the field id)
+> - The R column in the input parameters of the following methods all represent database fields. When the specific type of R is String, it is the database field name (the field name is the database keyword and it is wrapped by an escape character!)! Not the entity data field name! !!, when the specific type of R is SFunction, the project runtime does not support eclipse's own compiler!!!
+> - The following examples are all using ordinary wrappers, and the input parameters are Map and List in the form of json!
+> - If the input Map or List is empty during use, it will not be added to the final generated SQL!
+
+> **Warn:**
+> - Does not support and does not support the transmission of Wrapper in RPC calls
+>
+wrapper is heavy
+> - The transmission wrapper can be analogous to your controller using a map to receive the value (the development is cool, and the crematorium is maintained)
+> - The correct RPC call posture is to write a DTO for transmission, and the callee then performs corresponding operations based on the DTO
+> - We refuse to accept any issues or even pr related to RPC transmission Wrapper errors
+
diff --git a/docs/en/config.md b/docs/en/config.md
new file mode 100644
index 00000000..9c782057
--- /dev/null
+++ b/docs/en/config.md
@@ -0,0 +1,46 @@
+> **Basic configuration:**
+> If it is missing, it can cause the project to fail to start normally
+
+```yaml
+easy-es:
+ eanble: true # The default value is true, If the value of enable is false, it is considered that Easy-es is not enabled
+ address: 127.0.0.0:9200 # Your elasticsearch address,must contains port, If it is a cluster, please separate with',' just like this: 127.0.0.0:9200,127.0.0.1:9200
+ username: elastic # Es username, Not necessary, If it is not set in your elasticsearch, delete this line
+ password: WG7WVmuNMtM4GwNYkyWH # Es password, Not necessary, If it is not set, delete this line
+
+```
+> **Extended configuration:**
+> It can be defaulted, in order to improve production performance, you can configure it further (only supported in version 0.9.4+)
+
+```yaml
+easy-es:
+ connectTimeout: 5000 # Connection timeout unit: ms
+ socketTimeout: 5000 # Communication timeout unit: ms
+ requestTimeout: 5000 # Request timeout unit: ms
+ connectionRequestTimeout: 5000 # Connection request timeout
+ maxConnTotal: 100 # Maximum number of connections
+ maxConnPerRoute: 100 # Maximum number of connected routes
+```
+> **Global configuration:**
+> Can be defaulted, does not affect the project startup, if the default is the default value
+
+```yaml
+easy-es:
+ global-config:
+ db-config:
+ table-prefix: dev_ # Index prefix, can be used to distinguish the environment, the default is empty
+ id-type: auto # id generation strategy defaults to auto
+ field-strategy: not_empty # The field update strategy defaults to not_null, and the field is updated only when the field value is not empty
+
+```
+> **Tips:**
+> - id-type supports 2 types:
+>
+ auto: It is automatically generated by ES and is the default configuration, no additional configuration is required for you. Recommended
+> uuid: The system generates UUID, and then inserts ES (not recommended)
+> - Field-strategy supports 3 types:
+> - not_null: non-Null judgment, only when the field value is non-Null will be updated
+> - not_empty: non-empty judgment, will be updated only when the field value is a non-empty string
+> - ignore: Ignore the judgment, no matter what the field value is, it will be updated
+> - After configuring the global policy, you can still customize the configuration for individual classes through annotations, and the priority of the global configuration is lower than the annotation configuration
+
diff --git a/docs/en/contact.md b/docs/en/contact.md
new file mode 100644
index 00000000..f5742794
--- /dev/null
+++ b/docs/en/contact.md
@@ -0,0 +1,14 @@
+Base: Hangzhou
+
+developed as full-stack for 5 years, and has been a muscular man for 8 years. Welcome friends with similar smells to tease.
+
+If you are also interested in open source, welcome to join our technical team, we sincerely invite heroes from all over the world to work together to create better open source projects.
+
+
+At present, there is a Taobao store, which specializes in fitness supplements. The food industry has complete business licenses and a stable supply chain. However, due to the lack of time to operate, there are plans to revive in the future. [One-click fitness plan generation system](https://gitee.com/easy-es/fit-plan), which can be used to provide customers with free fitness plans.
+
+QQ|WeChat (same number) : 252645816
+
+Technology & Fitness Discussion Group: 247637156
+
+Because there is no group number and dynamic code in the WeChat group, if you want to join the WeChat group, you must add your own WeChat first, and then pull it in by yourself.
\ No newline at end of file
diff --git a/docs/en/copyright.md b/docs/en/copyright.md
new file mode 100644
index 00000000..f64f419b
--- /dev/null
+++ b/docs/en/copyright.md
@@ -0,0 +1,5 @@
+In order to maintain the syntax of this framework consistent with MP, some of the code comes from the open source framework [Mybatis-Plus](https://mp.baomidou.com/), or has been modified, which is specially stated here.
+
+The bottom layer of this framework uses ElasticSearch's official open source framework [RestHighLevelClient](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html), which is specifically stated here.
+
+This framework adopts the same [Apache2.0 License](https://www.apache.org/licenses/LICENSE-2.0) as Mybatis-plus, and promises to never participate in commercial use, and is only for free use by everyone.
diff --git a/docs/en/create-index.md b/docs/en/create-index.md
new file mode 100644
index 00000000..db82e4bd
--- /dev/null
+++ b/docs/en/create-index.md
@@ -0,0 +1,27 @@
+```java
+ @Test
+ public void testCreatIndex() {
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+ // For the sake of simplicity here, the index name must be consistent with the entity class name, with lowercase letters. Later chapters will teach you how to configure and use the index more flexibly
+ wrapper.indexName(Document.class.getSimpleName().toLowerCase());
+
+ // Here, the article title is mapped to the keyword type (word segmentation is not supported), and the document content is mapped to the text type (word segmentation query is supported), which can be defaulted
+ wrapper.mapping(Document::getTitle, FieldType.KEYWORD)
+ .mapping(Document::getContent, FieldType.TEXT);
+
+ // Set shard and replica information, here 3 shards and 2 replicas are set, which can be defaulted
+ wrapper.settings(3,2);
+
+ // Set alias information, which can be defaulted
+ String aliasName = "dev";
+ wrapper.createAlias(aliasName);
+
+ // execute create index
+ boolean isOk = documentMapper.createIndex(wrapper);
+ Assert.assertTrue(isOk);
+ }
+```
+> **Tips:**
+> Due to the feature of automatic reconstruction of ES index changes, the mapping, settings, and alias information required to create the index are three-in-one during the design of this interface. Although each configuration can be defaulted, we still recommend that you create the index plan the above information in advance to avoid unnecessary trouble caused by subsequent modifications. If there are subsequent modifications, you can still modify it by alias migration (recommended, smooth transition), or delete the original index and recreate it. .
+>
+
diff --git a/docs/en/del-index.md b/docs/en/del-index.md
new file mode 100644
index 00000000..ce509711
--- /dev/null
+++ b/docs/en/del-index.md
@@ -0,0 +1,10 @@
+> Delete the index, please operate with caution in the production environment, the recovery cost and difficulty are high
+
+```java
+ @Test
+ public void testDeleteIndex(){
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ boolean isOk = documentMapper.deleteIndex(indexName);
+ Assert.assertTrue(isOk);
+ }
+```
diff --git a/docs/en/delete.md b/docs/en/delete.md
new file mode 100644
index 00000000..feec3ede
--- /dev/null
+++ b/docs/en/delete.md
@@ -0,0 +1,16 @@
+```java
+Integer deleteById(Serializable id);
+// delete based on conditions
+Integer delete(LambdaEsQueryWrapper wrapper);
+Integer deleteBatchIds(Collection idList);
+```
+**Parameter Description**
+
+| Type | Parameter name | Description |
+| --- | --- | --- |
+| Wrapper | wrapper | Delete conditional packaging |
+| Serializable | id | primary key in es |
+| Collection | idList | primary key list in es |
+
+
+
diff --git a/docs/en/demo.md b/docs/en/demo.md
new file mode 100644
index 00000000..856b39a6
--- /dev/null
+++ b/docs/en/demo.md
@@ -0,0 +1,47 @@
+> This Demo demonstrates the use of Easy-Es in the Springboot project. It is recommended to download it first and run it directly on your local.
+> Demo download link: [Github](https://github.com/xpc1024/easy-es-springboot-demo-en)
+
+# Demo introduction
+
+---
+
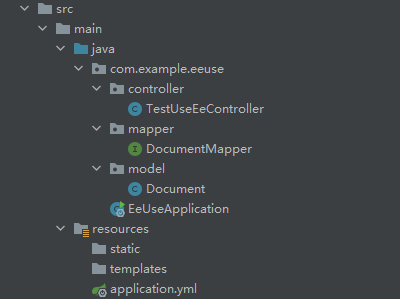
+## 1. Project structure
+
+---
+
+
+
+## 2.Configuration
+
+---
+
+```yaml
+easy-es:
+ eanble: true # The default value is true, If the value of enable is false, it is considered that Easy-es is not enabled
+ address: 127.0.0.0:9200 # Your elasticsearch address,must contains port, If it is a cluster, please separate with',' just like this: 127.0.0.0:9200,127.0.0.1:9200
+ username: elastic # Es username, Not necessary, If it is not set in your elasticsearch, delete this line
+ password: WG7WVmuNMtM4GwNYkyWH # Es password, Not necessary, If it is not set, delete this line
+
+```
+## 3.Run
+
+---
+
+Use your IDE to start the project: 
+
+## 4.Use
+
+---
+
+Use your browser or postman to request the following addresses in turn:
+
+- [http://localhost:8080/index](http://localhost:8080/index) (create index, must be requested first and only once)
+- [http://localhost:8080/insert](http://localhost:8080/insert) (create data)
+- [http://localhost:8080/search](http://localhost:8080/search) (search data)
+> Then you will get the result what you searched in your browser or postman.
+
+## 5.Summary
+
+---
+
+At this point, you have initially experienced the basic functions of Easy-Es. If you feel that the experience is good, and you want to further experience more powerful functions, you can check the reference document.
diff --git a/docs/en/donate.md b/docs/en/donate.md
new file mode 100644
index 00000000..16f58b54
--- /dev/null
+++ b/docs/en/donate.md
@@ -0,0 +1,21 @@
+> Your support is the motivation to encourage us to move forward, no matter how much money is, it is enough to express your wishes.
+
+author's wechat account or alipay:
+
+
+
+
+
+Visa Debit:
+
+6217930275445975 cardholder:pengcheng xing Bank:Shanghai Pudong Development Bank
+
+> - Please note for donations, we will upload your donation information to this page, and each donation can be publicized according to your wishes.
+> - There is no limit to the amount of donation, and there is currently no server. If you can donate a server or domain name, in return, we will place advertisements and donate information for you in the designated area of the page for free.
+
+Author's e-mail:252645816@qq.com
+
+
+
+
+
diff --git a/docs/en/eq.md b/docs/en/eq.md
new file mode 100644
index 00000000..241cebd7
--- /dev/null
+++ b/docs/en/eq.md
@@ -0,0 +1,5 @@
+```java
+eq(R column, Object val)
+eq(boolean condition, R column, Object val)
+```
+● equal to = ● Example: eq("name", "Jimmy")-->name ='Jimmy'
diff --git a/docs/en/exists-index.md b/docs/en/exists-index.md
new file mode 100644
index 00000000..b7fccadc
--- /dev/null
+++ b/docs/en/exists-index.md
@@ -0,0 +1,10 @@
+> Can be used to verify whether there is an index with the specified name
+
+```java
+ @Test
+ public void testExistsIndex(){
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ boolean existsIndex = documentMapper.existsIndex(indexName);
+ Assert.assertTrue(existsIndex);
+ }
+```
diff --git a/docs/en/faq.md b/docs/en/faq.md
new file mode 100644
index 00000000..42796db2
--- /dev/null
+++ b/docs/en/faq.md
@@ -0,0 +1,38 @@
+> Since EE has not been used by a large number of users, there is no FAQ for the time being, and it will continue to be updated in the future. Here are some common questions I encountered that may be asked
+
+1. During the trial process, an error was reported: java.lang.reflect.UndeclaredThrowableException
+```
+Caused by: [daily_document] ElasticsearchStatusException[Elasticsearch exception [type=index_not_found_exception, reason=no such index [daily_document]]]
+```
+If your error message and cause are consistent with the above, please check whether the index name is correctly configured, check the global configuration, and annotate the configuration. If the configuration is correct, it may be that the index does not exist. You can check whether the specified index already exists through the es-head visualization tool If there is no such index, it can be quickly created through the API provided by EE.
+
+2. Dependence conflict
+
+Although the EE framework is light enough and I try to avoid using too many other dependencies during the development process, it is still difficult to guarantee that dependency conflicts with the host project will occur with a very small probability. If there is a dependency conflict, the developer can use the migration Except for repetitive dependencies or unified version numbers to resolve, all EE dependencies that may conflict are as follows:
+```xml
+
+ org.projectlombok
+ lombok
+ 1.18.12
+
+
+ org.elasticsearch.client
+ elasticsearch-rest-high-level-client
+ 7.10.1
+
+
+ org.elasticsearch
+ elasticsearch
+ 7.10.1
+
+
+ com.alibaba
+ fastjson
+ 1.2.79
+
+
+ commons-codec
+ commons-codec
+ 1.6
+
+```
diff --git a/docs/en/field-anno.md b/docs/en/field-anno.md
new file mode 100644
index 00000000..e21c1f3d
--- /dev/null
+++ b/docs/en/field-anno.md
@@ -0,0 +1,26 @@
+> The field annotation @TableField function is the same as [Mybatis-Plus](https://github.com/baomidou/mybatis-plus)(Hereafter referred to as MP), but compared to MP, some low-frequency use functions have been castrated. Follow-up based on user feedback can be gradually added with the iteration. The current version currently only supports the following two scenarios:
+>
+> 1. The field in the entity class is not the actual field in ES. For example, the entity class is directly used as DTO, and some extraneous fields that do not exist in ES are added. At this time, this field can be marked so that the EE framework can skip this Field, this field is not processed.
+> 1. The update strategy of the field, for example, when the update interface is called, the field of the entity class is not updated until it is not Null or a non-empty string. At this time, you can add field annotations and mark the update strategy for the specified field.
+
+Example of use:
+```java
+ public class Document {
+ // Other fields are omitted here...
+
+ // Scenario 1: mark fields that do not exist in es
+ @TableField(exist = false)
+ private String notExistsField;
+
+ // Scenario 2: When updating, the non-empty string in this field will be updated
+ @TableField(strategy = FieldStrategy.NOT_EMPTY)
+ private String creator;
+ }
+```
+> **Tips:**
+> - There are 3 types of update strategies:
+> - NOT_NULL: Non-Null judgment, only when the field value is non-Null, it will be updated
+> - NOT_EMPTY: non-empty judgment, will be updated only when the field value is a non-empty string
+> - IGNORE: Ignore the judgment, no matter what the field value is, it will be updated
+> - Priority: The update strategy specified in the field annotations> the update strategy specified in the global configuration
+
diff --git a/docs/en/filter.md b/docs/en/filter.md
new file mode 100644
index 00000000..161fdac7
--- /dev/null
+++ b/docs/en/filter.md
@@ -0,0 +1,38 @@
+> If you don’t want to check some large fields in some queries, you can filter the query fields
+
+## 1.Forward filtering (only query specified fields)
+```java
+ @Test
+ public void testFilterField() {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "Hello";
+ wrapper.eq(Document::getTitle, title);
+ // only query title field
+ wrapper.select(Document::getTitle);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+ }
+```
+## 2.Reverse filtering (do not query the specified field)
+```java
+ @Test
+ public void testNotFilterField() {
+ // Do not query the specified field (recommended)
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "Hello";
+ wrapper.eq(Document::getTitle, title);
+ // don't select title field
+ wrapper.notSelect(Document::getTitle);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+
+ // Another way to achieve
+ LambdaEsQueryWrapper wrapper1 = new LambdaEsQueryWrapper<>();
+ wrapper1.select(Document.class, d -> !Objects.equals(d.getColumn(), "title"));
+ Document document1 = documentMapper.selectOne(wrapper);
+ System.out.println(document1);
+ }
+```
+> **Tips:**
+> You can only choose one of forward filtering and reverse filtering. If you use both filtering rules at the same time, the conflicting field will lose the filtering effect.
+
diff --git a/docs/en/from.md b/docs/en/from.md
new file mode 100644
index 00000000..b1b08c1d
--- /dev/null
+++ b/docs/en/from.md
@@ -0,0 +1,4 @@
+```java
+from(Integer from)
+```
+● Start the query from the first data, which is equivalent to m in limit (m,n) in MySQL. ● Example: from(10)--->Start query from the 10th data
diff --git a/docs/en/ge.md b/docs/en/ge.md
new file mode 100644
index 00000000..f34b061f
--- /dev/null
+++ b/docs/en/ge.md
@@ -0,0 +1,5 @@
+```java
+ge(R column, Object val)
+ge(boolean condition, R column, Object val)
+```
+● Greater than or equal to >= ● Example: ge("age", 18)--->age >= 18
diff --git a/docs/en/geo-bounding-box.md b/docs/en/geo-bounding-box.md
new file mode 100644
index 00000000..b2ceb331
--- /dev/null
+++ b/docs/en/geo-bounding-box.md
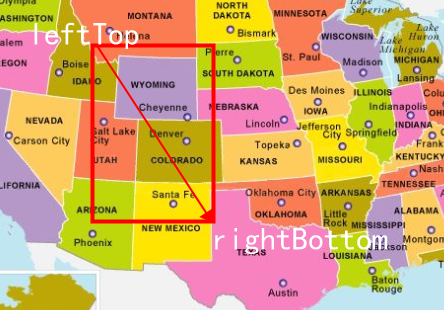
@@ -0,0 +1,42 @@
+GeoBoundingBox: Literally translated as a geographic bounding box, a rectangular range formed by the upper left point and the lower right point, all points within this range can be queried, but not many are actually used, please refer to the following figure:
+
+
+
+API:
+```java
+geoBoundingBox(R column, GeoPoint topLeft, GeoPoint bottomRight)
+```
+Example of use:
+```java
+@Test
+ public void testGeoBoundingBox() {
+ // Query all points within the rectangle formed by the coordinates of the upper left and lower right points
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ GeoPoint leftTop = new GeoPoint(41.187328D, 115.498353D);
+ GeoPoint bottomRight = new GeoPoint(39.084509D, 117.610461D);
+ wrapper.geoBoundingBox(Document::getLocation, leftTop, bottomRight);
+ List documents = documentMapper.selectList(wrapper);
+ documents.forEach(System.out::println);
+ }
+```
+> **Tips:**
+> 1. The above example only demonstrates one of them. In fact, there are many syntax support for coordinate points in this framework. Several data formats officially provided by ElasticSearch are supported. Users can choose the corresponding api according to their own habits to construct query parameters:
+> - **GeoPoint:** The latitude and longitude representation used in the demo above
+> - **Longitude and latitude array:**[116.498353, 40.187328],[116.610461, 40.084509]
+> - **Latitude and longitude strings:** "40.187328, 116.498353", "116.610461, 40.084509
+> - **Latitude and longitude bounding box WKT: **"BBOX (116.498353,116.610461,40.187328,40.084509)"
+> - **Latitude and longitude GeoHash (hash):** "xxx"
+>
+ Among them, the conversion of latitude and longitude hash can refer to this website: [GeoHash Coordinate Online Conversion](http://geohash.co/)
+>
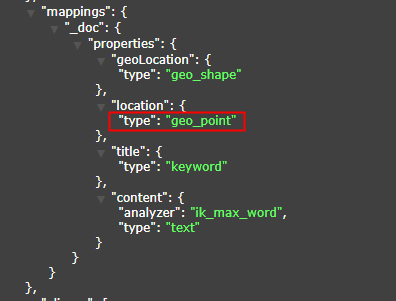
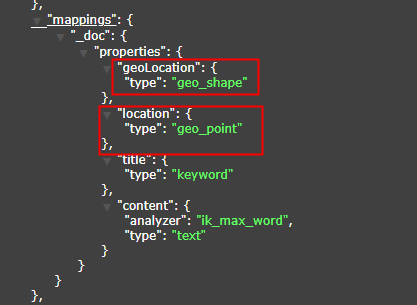
+> 2. The index type of the field must be geoPoint, otherwise the related query API will fail, please refer to the following figure.
+> 2. The field type is recommended to use String, because the wkt text format is String, which is very convenient. As for the field name, you can see the name.
+
+
+
+```java
+public class Document {
+ // Omit other fields ...
+ private String location;
+}
+```
diff --git a/docs/en/geo-distance.md b/docs/en/geo-distance.md
new file mode 100644
index 00000000..86e01fa8
--- /dev/null
+++ b/docs/en/geo-distance.md
@@ -0,0 +1,27 @@
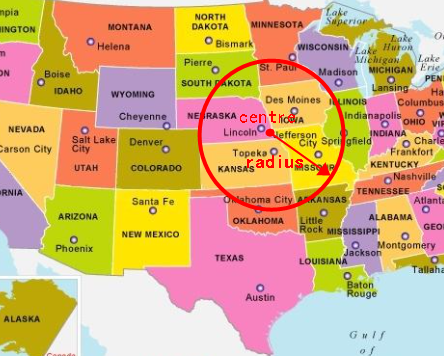
+GeoDistance: Literally translated as geographic distance, in fact, it takes a given point as the center, draws a circle with a given radius, and the points within this circle can be detected and used more frequently, such as the takeaway we use Software, you can use this function to query all the stores within 3 kilometers around, yes, you can also use it to write social software to query the beautiful women within 3 kilometers nearby...
+
+
+
+```java
+geoDistance(R column, Double distance, DistanceUnit distanceUnit, GeoPoint centralGeoPoint)
+```
+```java
+ @Test
+ public void testGeoDistance() {
+ // Query all points within a radius of 168.8 kilometers with a longitude of 41.0 and a latitude of 115.0 as the center and a radius of 168.8 kilometers.
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // The unit can be omitted, the default is km
+ wrapper.geoDistance(Document::getLocation, 168.8, DistanceUnit.KILOMETERS, new GeoPoint(41.0, 116.0));
+ // The above syntax can also be written in the following forms, the effect is the same, and it is compatible with different user habits:
+// wrapper.geoDistance(Document::getLocation,"1.5km",new GeoPoint(41.0,115.0));
+// wrapper.geoDistance(Document::getLocation, "1.5km", "41.0,115.0");
+
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+> Tips:
+> 1. The same form of expression for coordinate points is also supported, which is the same as the Tips in GeoBondingBox, and will not be repeated here.
+> 1. The index type and field type are the same as those described in the Tips in GeoBondingBox
+> 1. For fans of EE, it is a matter of course to be compatible with the different habits of various users, so you will find a lot of method overloading when you use it. Choose an API that best suits your usage habits or the specified usage scenario to call. .
+
diff --git a/docs/en/geo-polygon.md b/docs/en/geo-polygon.md
new file mode 100644
index 00000000..f79643d4
--- /dev/null
+++ b/docs/en/geo-polygon.md
@@ -0,0 +1,30 @@
+GeoPolygon: Literally translated as geographic polygon, in fact, it takes the polygon formed by all the given points as the range, and queries all the points within this range. This function is often used for electronic fences, and it is used more frequently, such as sharing bicycles. The parking area can be realized by this technology, please refer to the following figure:
+
+
+
+API:
+```java
+geoPolygon(R column, List geoPoints)
+```
+Example of use:
+```java
+ @Test
+ public void testGeoPolygon() {
+ // Query all points in an irregular graph composed of a given list of points, the number of points is at least 3
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ List geoPoints = new ArrayList<>();
+ GeoPoint geoPoint = new GeoPoint(40.178012, 116.577188);
+ GeoPoint geoPoint1 = new GeoPoint(40.169329, 116.586315);
+ GeoPoint geoPoint2 = new GeoPoint(40.178288, 116.591813);
+ geoPoints.add(geoPoint);
+ geoPoints.add(geoPoint1);
+ geoPoints.add(geoPoint2);
+ wrapper.geoPolygon(Document::getLocation, geoPoints);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+> **Tips:**
+> 1. Similarly, regarding the input parameter form of the coordinate point, it also supports a variety of forms. It is consistent with the official. You can refer to the Tips in GeoBoundingBox, which will not be repeated here. It is worth noting that the number of points in the polygon cannot be less than 3, otherwise Es cannot outline the polygon. , this query will report an error.
+> 1. The index type and field type are the same as those described in the Tips in GeoBondingBox
+
diff --git a/docs/en/geo-shape.md b/docs/en/geo-shape.md
new file mode 100644
index 00000000..15208921
--- /dev/null
+++ b/docs/en/geo-shape.md
@@ -0,0 +1,65 @@
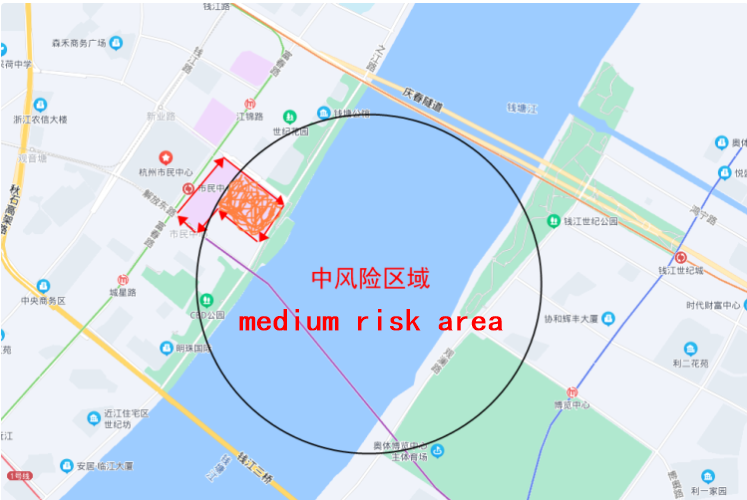
+GeoShape: Literally translated as geographic graphics, how do you understand it? At first glance, it seems to be very similar to GeoPolygon, but in fact, the first three types of queries are all coordinate points, and this method queries graphics, such as a park, from the world map. It can be regarded as a point, but if the map is made large enough, for example, the map is specific to Binjiang District, Hangzhou, the park may become an area composed of several points. In some special scenarios, you need to query this complete Area, and the intersection of two areas, etc., you need to use GeoShape. If you don’t understand it, you might as well read it down first. Take Hangzhou as an example. I will give an example of a health code, assuming the area inside the black circle. For the medium-risk area, I now want to find out all the people in the ES who are in the civic center and in the medium-risk area, and turn all their health codes into orange. In fact, what I am looking for is the orange area in the picture below. At this time, the area formed by the red arrow is the entire civic center. I can use the entire civic center as a geographic graph, and then use the large black circle as the query graph to find their intersection.
+
+
+
+The ShapeRelation corresponding to the above figure is INTERSECTS, take a look at the following API.
+
+API:
+```java
+geoShape(R column, String indexedShapeId);
+
+geoShape(R column, Geometry geometry, ShapeRelation shapeRelation);
+```
+Example of use: This API is not commonly used, you can also skip directly to see the query by graph below.
+```java
+ /**
+ * Known graphics index ID (not commonly used)
+ * In some high-frequency scenarios, such as a park that has already been built, the graphics coordinates are fixed, so this fixed graphics can be stored in es first
+ * Follow-up can be directly queried based on the id of this graph, which is more convenient, so there is this method, but it is not flexible enough and not commonly used
+ */
+ @Test
+ public void testGeoShapeWithShapeId() {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // The indexedShapeId here is the id of the shape that the user has created in Es in advance
+ wrapper.geoShape(Document::getGeoLocation, "edu");
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+This API is more commonly used than the above method, that is, the user can specify whether the graph to be queried is a rectangle, a circle, or a polygon... (see the comments in the code for details):
+```java
+ /**
+ * Graphics are customized by users (commonly used), this framework supports all supported graphics of Es:
+ * (Point,MultiPoint,Line,MultiLine,Circle,LineaRing,Polygon,MultiPolygon,Rectangle)
+ */
+ @Test
+ public void testGeoShape() {
+ // Note that the graph is queried here, so the field index type of the graph must be geoShape, not geoPoint, so the geoLocation field is used instead of the location field
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ Circle circle = new Circle(13,14,100);
+ // shapeRelation supports multiple types, if not passed, it defaults to within
+ wrapper.geoShape(Document::getGeoLocation, circle, ShapeRelation.INTERSECTS);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+in the above map
+
+WKT (Well-Known Text) coordinates of the civic center (polygon) (simulated data, real data can be obtained from AutoNavi Map/Baidu Map, etc. by calling the open API provided by them): "POLYGON((108.36549282073975 22.797566864832092,108.35974216461182 22.786093175673713)
+
+It has been stored in Es. In fact, we will store all the data or business data that may be used in the project in Es in advance. Otherwise, the query will be meaningless. Check the air?
+
+So when the above API queries based on GeoShape, the parameter that needs to be passed in is only the graph of the range you delineate (the parameter above is a circle).
+> **TIps:**
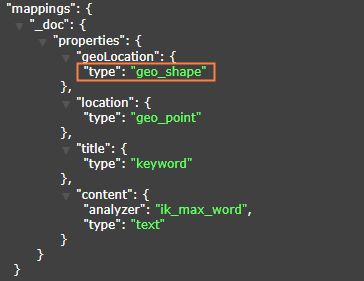
+> - GeoShape is easy to be confused with GeoPolygon and needs special attention, they are actually two different things.
+> - The field index type for GeoShape query must be geo_shape type, otherwise this API cannot be used, refer to the following figure
+> - The field type is recommended to use String, because the wkt text format is String, which is very convenient. As for the field name, you can see the name.
+
+
+
+```java
+public class Document {
+ // Omit other fields ...
+ private String geoLocation;
+}
+```
diff --git a/docs/en/geo.md b/docs/en/geo.md
new file mode 100644
index 00000000..1f3d2e1d
--- /dev/null
+++ b/docs/en/geo.md
@@ -0,0 +1,40 @@
+> Supported Versions: 0.9.5+
+> Geographical location query, which is exactly the same as the function provided by Es official, supports a total of 4 types of geographic location query:
+> - GeoBoundingBox
+> - GeoDistance
+> - GeoPolygon
+> - GeoShape
+>
+Through these four types of queries, various powerful and practical functions can be realized
+
+Application Scenario:
+
+● Stores near takeaway apps
+
+● People near social apps
+
+● Drivers near taxi apps
+
+● Crowd feature extraction within the specified range of regional crowd portrait APPs
+
+● Health code, etc.
+
+● ...
+
+The function coverage is 100%, and the use is simpler. For the detailed introduction of the 4 types of queries, please click the left menu to enter the sub-items to view
+> **Tips:**
+> 1. Before using the geolocation query API, you need to create or update the index in advance
+> - The first three types of API (GeoBoundingBox, GeoDistance, GeoPolygon) field index type must be geo_point
+> - GeoShape field index type must be geo_shape, please refer to the following figure for details
+>
+> 2.The field type is recommended to use String, because the wkt text format is String, which is very convenient. As for the field name, you can see the name.
+
+
+
+```java
+public class Document {
+ // Omit other fields...
+ private String location;
+ private String geoLocation;
+}
+```
diff --git a/docs/en/groupBy.md b/docs/en/groupBy.md
new file mode 100644
index 00000000..a9514d0d
--- /dev/null
+++ b/docs/en/groupBy.md
@@ -0,0 +1,5 @@
+```java
+groupBy(R... columns)
+groupBy(boolean condition, R... columns)
+```
+● Grouping: GROUP BY field, ... ● Example: groupBy(Document::getId,Document::getTitle)--->group by id,title
diff --git a/docs/en/gt.md b/docs/en/gt.md
new file mode 100644
index 00000000..4c1cee92
--- /dev/null
+++ b/docs/en/gt.md
@@ -0,0 +1,5 @@
+```java
+gt(R column, Object val)
+gt(boolean condition, R column, Object val)
+```
+● Greater than> ● Example: gt("age", 18)--->age> 18
diff --git a/docs/en/highlight.md b/docs/en/highlight.md
new file mode 100644
index 00000000..88fd19e9
--- /dev/null
+++ b/docs/en/highlight.md
@@ -0,0 +1,22 @@
+**syntax:**
+```java
+// Do not specify the highlight tag, and use your highlight content to return the highlighted content by default
+highLight(highlightField);
+// Specify highlight label
+highLight(highlightField,startTag, endTag)
+```
+```java
+ @Test
+ public void testHighlight() throws IOException {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "World";
+ wrapper.match(Document::getContent,keyword);
+ wrapper.highLight(Document::getContent);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> **Tips:**
+> If you need to highlight multiple fields, you can separate the fields with commas
+> Must use SearchResponse to receive, otherwise there is no highlighted field in the return body
+
diff --git a/docs/en/hybrid-query.md b/docs/en/hybrid-query.md
new file mode 100644
index 00000000..c0b10f65
--- /dev/null
+++ b/docs/en/hybrid-query.md
@@ -0,0 +1,47 @@
+# What is a mixed query?
+A simple understanding is that half of it adopts the syntax of EE, and half of it adopts the syntax of RestHighLevelClient, which is similar to "Hybrid". I believe you will fall in love with this "Hybrid" mode, because it combines the advantages of both modes!
+# Why have hybrid queries?
+Because EE has not yet achieved 100% coverage of the functions of RestHighLevelClient, at the initial stage of open source, it only covers about 90% of the functions of RestHighLevelClient, and 99% of the core high-frequency use functions, so it is inevitable that there will be individual scenarios. EE cannot meet a certain special requirement. At this time, the secondary development of the EE framework or the requirement is directly submitted to the EE author, which cannot meet the developer's needs in terms of time. Some requirements may be tighter than the product manager. , you can solve the dilemma by mixing queries.
+# How to use hybrid query?
+When I did not provide this document, although I provided an API and a brief introduction to the mixed query, many people still do not know this function, let alone how to use it, so here I will use a specific case to demonstrate to you How to use mixed query is for your reference, please don't worry about the space, it's actually very, very simple, just the details of my tutorial.
+
+> **Background:** User "Xiangyang" WeChat feedback to me that currently EE does not support query sorting from near to far from a given point.
+> In actual development, this scenario can be applied to "the passenger places an order and asks to give priority to the driver closest to me within 3 kilometers" when taking a taxi, and then the passenger is a beautiful woman, worried about her own safety, and added a few more requirements. , For example, the driver must be a female, the driving experience is more than 3 years, and the commercial vehicle, etc...
+
+
+Taking the taxi-hailing scenario above as an example, let's see how to use EE to query? The above query can be divided into two parts
+
+● Routine queries supported by EE: If the driver is female within 3 kilometers of the surrounding area, and the driving age is >= 3 years...
+
+● Unconventional queries not supported by EE: sorting according to complex sorting rules (currently EE only supports ascending/descending sorting of regular fields)
+
+For the supported part, we can directly call EE, and EE builds a SearchSourceBuilder first.
+
+```java
+// Suppose the latitude and longitude of the passenger's location is 31.256224D, 121.462311D
+LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+wrapper.geoDistance(Driver::getLocation, 3.0, DistanceUnit.KILOMETERS, new GeoPoint(31.256224D, 121.462311D));
+ .eq(Driver::getGender,"Female")
+ .ge(Driver::getDriverAge,3)
+ .eq(Driver::getCarModel,"business car");
+SearchSourceBuilder searchSourceBuilder = driverMapper.getSearchSourceBuilder(wrapper);
+```
+For unsupported statements, you can continue to encapsulate them with the syntax of RestHighLevelClient. After encapsulation, you can directly call the native query interface provided by EE to complete the entire query.
+```java
+SearchRequest searchRequest = new SearchRequest("indexName");
+// The searchSourceBuilder here is constructed from the above EE, and we continue to append sorting parameters to it
+searchSourceBuilder.sort(
+ new GeoDistanceSortBuilder("location", 31.256224D, 121.462311D)
+ .order(SortOrder.DESC)
+ .unit(DistanceUnit.KILOMETERS)
+ .geoDistance(GeoDistance.ARC)
+);
+searchRequest.source(searchSourceBuilder);
+SearchResponse searchResponse = driverMapper.search(searchRequest, RequestOptions.DEFAULT);
+```
+In this way, you can not only enjoy the basic queries generated by EE for you, but also complete the functions that EE does not currently support. You only need a lot of code (compared to the direct RestHighLevelClient, it can still save a lot of code) to achieve your The goal is similar to a compromise solution under the condition that pure electric vehicles have not yet fully developed, namely gasoline-electric hybrid.
+
+Of course, if you are not used to using this mode, you can still use the native query directly, so you can use EE without any worries. We have already figured out various solutions and fallbacks for you, and after-sales is worry-free! If you also agree with this model, you may wish to give the author a thumbs up. In order to make EE users happy, the author's bad old man can be described as painstaking!
+
+# Epilogue
+Because the functions supported by RestHighLevel officially provided by ES are really too numerous, although I am still integrating various new functions non-stop, and repairing user feedback problems, optimizing the performance of existing code, but there will inevitably be some The function can not meet your current needs, please forgive me, my lords, EE has only been born for three months, it is impossible to be perfect, please give us a little time, these so-called shortcomings will be solved, just like new energy vehicles will eventually be in the future. Gradually replace the fuel car, those so-called problems will not be a problem in the future, Ullah!
diff --git a/docs/en/id-anno.md b/docs/en/id-anno.md
new file mode 100644
index 00000000..2fb412a7
--- /dev/null
+++ b/docs/en/id-anno.md
@@ -0,0 +1,25 @@
+> The primary key annotation @TableId function is the same as[ Mybatis-Plus](https://github.com/baomidou/mybatis-plus)(Hereafter referred to as MP), but compared to MP, some low-frequency usage functions have been castrated. According to user feedback, it can be added gradually with the iteration. The current version currently only supports the following two scenarios:
+>
+> 1. Rename the unique id in es
+> 1. Specify the unique id generation method in es
+
+Example:
+```java
+public class Document {
+ /**
+ * unique id in es
+ */
+ @TableId(value = "myId",type = IdType.AUTO)
+ private String id;
+
+ // Omit other fields...
+}
+```
+> **Tips:**
+> - Since es has processed the default name of id (underscore + id): _id, EE has blocked this operation for you, you don't need to specify it in the annotation, and the framework will automatically complete the mapping for you.
+> - Id generation types currently only support three types:
+> 1. **IdType.AUTO:** It is automatically generated by ES and is the default configuration, no additional configuration is required for you. Recommended
+> 1. **IdType.UUID:** The system generates UUID, and then inserts ES (not recommended)
+> 1. **IdType.CUSTOMIZE:** (version number >= 0.9.6 support) is defined by the user, the user sets the id value by himself, if the id specified by the user does not exist in es, a new record will be added when inserting, if If the user-specified id already has a record in es, the record corresponding to the id will be updated automatically.
+> - **Priority:** Annotation configured Id generation strategy>Globally configured Id generation strategy
+
diff --git a/docs/en/in.md b/docs/en/in.md
new file mode 100644
index 00000000..654fbb69
--- /dev/null
+++ b/docs/en/in.md
@@ -0,0 +1,11 @@
+```java
+in(R column, Collection value)
+in(boolean condition, R column, Collection value)
+```
+● Field in (value.get(0), value.get(1), ...) ● Example: in("age",{1,2,3})--->age in (1,2,3)
+
+```java
+in(R column, Object... values)
+in(boolean condition, R column, Object... values)
+```
+● Field in (v0, v1, ...) ● Example: in("age", 1, 2, 3)--->age in (1,2,3)
diff --git a/docs/en/index-alias.md b/docs/en/index-alias.md
new file mode 100644
index 00000000..dae51780
--- /dev/null
+++ b/docs/en/index-alias.md
@@ -0,0 +1,7 @@
+```java
+/**
+ * Set alias information
+ * @param aliasName
+ */
+createAlias(String aliasName)
+```
diff --git a/docs/en/index-anno.md b/docs/en/index-anno.md
new file mode 100644
index 00000000..114e1100
--- /dev/null
+++ b/docs/en/index-anno.md
@@ -0,0 +1,17 @@
+> - Index If the user does not configure or specify an annotation, the lowercase letters of the model name will be used as the index. For example, if the model is called Document, then the index will be document.
+> - We also support specifying the index name according to the @TableName annotation.In order to maintain the same syntax as MP, the annotation naming here will temporarily retain @TableName, but it actually represents the index name.
+
+Usage example: Assuming that my index name is: dev_document, then we can add this annotation to the model
+```java
+@TableName("dev_document")
+public class Document {
+ ...
+}
+```
+> Tips:
+> - The index name specified by the annotation has the highest priority. If the annotation index is specified, the global configuration and automatically generated index will not take effect, and the index name specified in the annotation will be used. Priority order: Annotation index>Global configuration index prefix>Auto generated
+> - The keepGlobalPrefix option, (only supported in version 0.9.4+), the default value is false, whether to keep using the global tablePrefix value:
+> - This annotation option will only take effect when the global tablePrefix is configured, the @TableName annotation and the value value are specified. If its value is true, the index name finally used by the framework is: global tablePrefix + the value of this annotation, for example: dev_document.
+> - The usage of this annotation tab is the same as in Mybatis-Plus.
+>
+
diff --git a/docs/en/index-shard.md b/docs/en/index-shard.md
new file mode 100644
index 00000000..879540d5
--- /dev/null
+++ b/docs/en/index-shard.md
@@ -0,0 +1,9 @@
+```java
+/**
+ * Set the number of shards and replicas of the index
+ *
+ * @param shards number of shards
+ * @param replicas Number of replicas
+ */
+settings(Integer shards, Integer replicas);
+```
diff --git a/docs/en/index.md b/docs/en/index.md
new file mode 100644
index 00000000..01d947b8
--- /dev/null
+++ b/docs/en/index.md
@@ -0,0 +1,11 @@
+> The EE index module provides the following APIs for users to make convenient calls
+> - indexName needs to be manually specified by the user
+> - Object Wrapper is conditional constructor
+
+```yaml
+Boolean existsIndex(String indexName);
+Boolean createIndex(LambdaEsIndexWrapper wrapper);
+Boolean updateIndex(LambdaEsIndexWrapper wrapper);
+Boolean deleteIndex(String indexName);
+```
+Please click the outline according to the name to enter the specific page to view the corresponding code of the interface
diff --git a/docs/en/insert.md b/docs/en/insert.md
new file mode 100644
index 00000000..03c8a091
--- /dev/null
+++ b/docs/en/insert.md
@@ -0,0 +1,14 @@
+```java
+// insert one record
+Integer insert(T entity);
+// batch insert
+Integer insertBatch(Collection entityList)
+```
+**Parameter Description**
+
+| Type | Parameter name | Description |
+| --- | --- | --- |
+| T | entity | The entity that needs to be inserted |
+| Collection | entityList | The entity list that needs to be inserted |
+
+
diff --git a/docs/en/isNotNull.md b/docs/en/isNotNull.md
new file mode 100644
index 00000000..bd095e79
--- /dev/null
+++ b/docs/en/isNotNull.md
@@ -0,0 +1,5 @@
+```java
+isNotNull(R column)
+isNotNull(boolean condition, R column)
+```
+● Field IS NOT NULL ● Example: isNotNull(Document::getTitle)--->title is not null
diff --git a/docs/en/isNull.md b/docs/en/isNull.md
new file mode 100644
index 00000000..d26d389f
--- /dev/null
+++ b/docs/en/isNull.md
@@ -0,0 +1,5 @@
+```java
+isNull(R column)
+isNull(boolean condition, R column)
+```
+● Field IS NULL ● Example: isNull(Document::getTitle)--->title is null
diff --git a/docs/en/le.md b/docs/en/le.md
new file mode 100644
index 00000000..921f6d3b
--- /dev/null
+++ b/docs/en/le.md
@@ -0,0 +1,5 @@
+```java
+le(R column, Object val)
+le(boolean condition, R column, Object val)
+```
+● Less than or equal to <= ● Example: le("age", 18)--->age <= 18
diff --git a/docs/en/like.md b/docs/en/like.md
new file mode 100644
index 00000000..3afa930d
--- /dev/null
+++ b/docs/en/like.md
@@ -0,0 +1,5 @@
+```java
+like(R column, Object val)
+like(boolean condition, R column, Object val)
+```
+● LIKE'%value%' ● Example: like("name", "James")--->name like'%James%'
diff --git a/docs/en/likeLeft.md b/docs/en/likeLeft.md
new file mode 100644
index 00000000..3aaa7d89
--- /dev/null
+++ b/docs/en/likeLeft.md
@@ -0,0 +1,5 @@
+```java
+likeLeft(R column, Object val)
+likeLeft(boolean condition, R column, Object val)
+```
+● LIKE'% value' ● Example: likeLeft("name", "James")--->name like'%James'
diff --git a/docs/en/likeRight.md b/docs/en/likeRight.md
new file mode 100644
index 00000000..062d31f3
--- /dev/null
+++ b/docs/en/likeRight.md
@@ -0,0 +1,5 @@
+```java
+likeRight(R column, Object val)
+likeRight(boolean condition, R column, Object val)
+```
+● LIKE'value%' ● Example: likeRight("name", "James")--->name like'James%'
diff --git a/docs/en/limit.md b/docs/en/limit.md
new file mode 100644
index 00000000..d77f5ddd
--- /dev/null
+++ b/docs/en/limit.md
@@ -0,0 +1,11 @@
+```java
+limit(Integer n);
+
+limit(Integer m, Integer n);
+```
+● limit n is the maximum number of pieces of data returned, which is equivalent to n in limit n in MySQL, and the usage is the same. ● limit m,n skip m pieces of data and return n pieces of data at most, which is equivalent to limit m,n or offset m limit n in MySQL ● Example: limit(10)--->Only return up to 10 pieces of data ● Example: limit(2,5)--->Skip the first 2 pieces of data, start the query from the 3rd piece, and query 5 pieces of data in total
+
+> **Tips:** If the n parameter is not specified, its default value is 10000
+> If you do a single query and don't want too many low-scoring data, you need to manually specify n to limit it.
+> In addition, the function of this parameter is consistent with the size and from in Es. It is only introduced for compatibility with MySQL syntax. Users can choose one of the two according to their own habits. When both are used, only one will take effect, and the later specified will override the first specified. of.
+
diff --git a/docs/en/lt.md b/docs/en/lt.md
new file mode 100644
index 00000000..a12933b4
--- /dev/null
+++ b/docs/en/lt.md
@@ -0,0 +1,5 @@
+```java
+lt(R column, Object val)
+lt(boolean condition, R column, Object val)
+```
+● Less than < ● Example: lt("age", 18)--->age <18
diff --git a/docs/en/match.md b/docs/en/match.md
new file mode 100644
index 00000000..93e9462c
--- /dev/null
+++ b/docs/en/match.md
@@ -0,0 +1,7 @@
+```java
+match(R column, Object val)
+match(boolean condition, R column, Object val)
+```
+> ● Word segment matching
+> ● Example: match("content", "someone")--->content contains the keyword "someone". If the word segmentation granularity is set finer, someone may be split into "some" and "one". As long as the content contains "some" or "one", it can be searched out
+
diff --git a/docs/en/ne.md b/docs/en/ne.md
new file mode 100644
index 00000000..ae2742fe
--- /dev/null
+++ b/docs/en/ne.md
@@ -0,0 +1,5 @@
+```java
+ne(R column, Object val)
+ne(boolean condition, R column, Object val)
+```
+● Not equal to != ● Example: ne("name", "Jimmy")--->name != 'Jimmy'
diff --git a/docs/en/notBetween.md b/docs/en/notBetween.md
new file mode 100644
index 00000000..69095f5b
--- /dev/null
+++ b/docs/en/notBetween.md
@@ -0,0 +1,5 @@
+```java
+notBetween(R column, Object val1, Object val2)
+notBetween(boolean condition, R column, Object val1, Object val2)
+```
+● NOT BETWEEN value 1 AND value 2 ● Example: notBetween("age", 18, 30)--->age not between 18 and 30
diff --git a/docs/en/notIn.md b/docs/en/notIn.md
new file mode 100644
index 00000000..75278e84
--- /dev/null
+++ b/docs/en/notIn.md
@@ -0,0 +1,11 @@
+```java
+notIn(R column, Collection value)
+notIn(boolean condition, R column, Collection value)
+```
+● Field not in (value.get(0), value.get(1), ...) ● Example: notIn("age",{1,2,3})--->age not in (1,2,3)
+
+```java
+notIn(R column, Object... values)
+notIn(boolean condition, R column, Object... values)
+```
+● Field not in (v0, v1, ...) ● Example: notIn("age", 1, 2, 3)--->age not in (1,2,3)
diff --git a/docs/en/notLike.md b/docs/en/notLike.md
new file mode 100644
index 00000000..3c7113b0
--- /dev/null
+++ b/docs/en/notLike.md
@@ -0,0 +1,5 @@
+```java
+notLike(R column, Object val)
+notLike(boolean condition, R column, Object val)
+```
+● NOT LIKE'%value%' ● Example: notLike("name", "James")--->name not like'%James%'
diff --git a/docs/en/or.md b/docs/en/or.md
new file mode 100644
index 00000000..3aaf2756
--- /dev/null
+++ b/docs/en/or.md
@@ -0,0 +1,10 @@
+```java
+or()
+or(boolean condition)
+```
+● Note for splicing OR: Actively calling or means that the next method is not connected with and! (If you don't call or, the default is to connect with and) ● Example: eq("Document::getId",1).or().eq(Document::getTitle,"Hello")--->id = 1 or title ='Hello'
+```java
+or(Consumer consumer)
+or(boolean condition, Consumer consumer)
+```
+● OR nesting ● Example: or(i -> i.eq(Document::getTitle, "Hello").ne(Document::getCreator, "Guy"))--->or (title ='Hello' and status != 'Guy' )
diff --git a/docs/en/orderBy.md b/docs/en/orderBy.md
new file mode 100644
index 00000000..b42e96f2
--- /dev/null
+++ b/docs/en/orderBy.md
@@ -0,0 +1,4 @@
+```java
+orderBy(boolean condition, boolean isAsc, R... columns)
+```
+● Sorting: ORDER BY field, ... ● Example: orderBy(true, true, Document::getId,Document::getTitle)--->order by id ASC,title ASC
diff --git a/docs/en/orderByAsc.md b/docs/en/orderByAsc.md
new file mode 100644
index 00000000..22ccde2b
--- /dev/null
+++ b/docs/en/orderByAsc.md
@@ -0,0 +1,5 @@
+```java
+orderByAsc(R... columns)
+orderByAsc(boolean condition, R... columns)
+```
+● Sort: ORDER BY field, ... ASC ● Example: orderByAsc(Document::getId,Document::getTitle)--->order by id ASC,title ASC
diff --git a/docs/en/orderByDesc.md b/docs/en/orderByDesc.md
new file mode 100644
index 00000000..8f92e84e
--- /dev/null
+++ b/docs/en/orderByDesc.md
@@ -0,0 +1,5 @@
+```java
+orderByDesc(R... columns)
+orderByDesc(boolean condition, R... columns)
+```
+● Sorting: ORDER BY field, ... DESC ● Example: orderByDesc(Document::getId,Document::getTitle)--->order by id DESC,title DESC
diff --git a/docs/en/origin-query.md b/docs/en/origin-query.md
new file mode 100644
index 00000000..4df0cd9c
--- /dev/null
+++ b/docs/en/origin-query.md
@@ -0,0 +1,11 @@
+```java
+ // Semi-native query
+ SearchResponse search(LambdaEsQueryWrapper wrapper) throws IOException;
+
+ // Standard native query can specify RequestOptions
+ SearchResponse search(SearchRequest searchRequest, RequestOptions requestOptions) throws IOException;
+```
+> **Tips:**
+> - In some high-level syntax, such as specifying the highlighted field, if our return type is the entity object itself, but there is usually no highlighted field in the entity, the highlighted field cannot be received. At this time, RestClietn's native return object SearchResponse can be used.
+> - Although EE covers most of the scenarios where we use ES, there may still be scenarios that are not covered. At this time, you can still query through the native grammar provided by RestClient and call the standard native query method. Both input and return are RestClient native
+
diff --git a/docs/en/page.md b/docs/en/page.md
new file mode 100644
index 00000000..f8041601
--- /dev/null
+++ b/docs/en/page.md
@@ -0,0 +1,18 @@
+```java
+ // The return type is not specified, and the paging parameter is not specified (the current page is 1 by default, and the total number of queries is 10), suitable for queries with high-level grammar
+ PageInfo pageQueryOriginal(LambdaEsQueryWrapper wrapper) throws IOException;
+
+ // No return type specified, paging parameters specified, suitable for queries with high-level syntax
+ PageInfo pageQueryOriginal(LambdaEsQueryWrapper wrapper, Integer pageNum, Integer pageSize) throws IOException;
+
+ // 指定返回类型,但未指定分页参数(默认按当前页为1,总查询条数10条)
+ PageInfo pageQuery(LambdaEsQueryWrapper wrapper);
+
+ // Specify the return type and paging parameters
+ PageInfo pageQuery(LambdaEsQueryWrapper wrapper, Integer pageNum, Integer pageSize);
+```
+> **Tips:**
+> - You can use paging query without integrating any plug-ins. This query belongs to physical paging.
+> - In some high-level grammar usage scenarios, due to the return of highlighting, aggregation and other fields, it is recommended to use the native SearchHit to receive the result set. Otherwise, because the entity itself does not contain fields such as highlighting and aggregation, this type of Field is missing.
+> - Note that PageInfo is provided by this framework. If you already have the most popular open source paging plugin [PageHelper](https://github.com/pagehelper/Mybatis-PageHelper) in your project, please be careful not to introduce errors when importing the package. EE uses the same return fields as PageHelper, so you don't need to worry about the field names. The extra workload caused by inconsistency.
+
diff --git a/docs/en/particple.md b/docs/en/particple.md
new file mode 100644
index 00000000..e8e519ad
--- /dev/null
+++ b/docs/en/particple.md
@@ -0,0 +1,12 @@
+> The word segmentation query is unique to Es. It is a query that is not supported in MySQL, that is, you can match according to keywords. There is not much introduction about word segmentation query. If you don't know it, please Google search to understand the concept, here only the usage is introduced.
+
+```java
+ @Test
+ public void testMatch(){
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "w";
+ wrapper.match(Document::getContent,keyword);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
diff --git a/docs/en/quick-start.md b/docs/en/quick-start.md
new file mode 100644
index 00000000..14d4caf2
--- /dev/null
+++ b/docs/en/quick-start.md
@@ -0,0 +1,226 @@
+We will use a simple Demo to illustrate the powerful functions of Easy-Es. Before that, we assume that you have
+
+● Have a Java development environment and corresponding IDE
+
+● Familiar with MySQL
+
+● Familiar with Spring Boot
+
+● Familiar with Maven
+
+● Understand the basic concepts of Es
+
+● Es is installed Recommended version 7.x+ (you can search for tutorials on Google if you don't have it, it is recommended to install another [es-head plugin](https://github.com/mobz/elasticsearch-head))
+
+> **TIP**
+> If you are too lazy to read the following tutorials, you can also download the [Springboo integrated demo](/en/demo.md) and run it directly
+
+## Initialize the project
+
+---
+
+Create an empty Spring Boot project
+> **TIP**
+> You can use [Spring Initializer](https://start.spring.io/) to quickly initialize a Spring Boot project
+
+## Add dependency
+
+---
+
+**Maven:**
+```xml
+
+ io.github.xpc1024
+ easy-es-boot-starter
+ Latest Version
+
+```
+**Gradle:**
+```groovy
+compile group: 'io.github.xpc1024', name: 'easy-es-boot-starter', version: 'Latest Version'
+```
+> **Tips:** Latest Version: [Click here to get the latest version](https://img.shields.io/github/v/release/xpc1024/easy-es?include_prereleases&logo=xpc&style=plastic)
+
+## Configuration
+
+---
+
+Add the necessary configuration of EasyEs in the application.yml configuration file:
+```yaml
+easy-es:
+ eanble: true # The default value is true, If the value of enable is false, it is considered that Easy-es is not enabled
+ address: 127.0.0.0:9200 # Your elasticsearch address,must contains port, If it is a cluster, please separate with',' just like this: 127.0.0.0:9200,127.0.0.1:9200
+ username: elastic # Es username, Not necessary, If it is not set in your elasticsearch, delete this line
+ password: WG7WVmuNMtM4GwNYkyWH # Es password, Not necessary, If it is not set, delete this line
+```
+> Other configurations can be omitted temporarily, the following chapters will introduce the configuration of EasyEs in detail
+
+Add the @EsMapperScan annotation to the Spring Boot startup class to scan the Mapper folder:
+```java
+@SpringBootApplication
+@EsMapperScan("com.xpc.easyes.sample.mapper")
+public class Application {
+
+ public static void main(String[] args) {
+ SpringApplication.run(Application.class, args);
+ }
+
+}
+```
+## backgrounds
+
+---
+
+There is currently a Document table. As the amount of data expands, its query efficiency can no longer meet product requirements. The table structure is as follows. We plan to migrate the content of this table to the Elasticsearch to improve query efficiency.
+
+| id | title | content |
+| --- | --- | --- |
+
+## coding
+
+---
+
+Write the entity class Document.java ([Lombok](https://www.projectlombok.org/) is used here to simplify the code)
+```java
+@Data
+public class Document {
+ /**
+ * just like the primary key in MySQL
+ */
+ private String id;
+
+ /**
+ * title of document
+ */
+ private String title;
+ /**
+ * content of document
+ */
+ private String content;
+
+ /**
+ * creator of document
+ */
+ private String creator;
+}
+```
+> **Tips:** If there is no annotation and global configuration for the above field id, its strategy is automatically generated by Es by default. The corresponding field in es is'_id', and the field type is String. If you need to perform special processing on the id, it will be introduced in the subsequent chapters. How to configure Id.
+
+Write the Mapper class DocumentMapper.java
+```java
+public interface DocumentMapper extends BaseEsMapper {
+}
+```
+## Get started (CRUD)
+
+---
+
+Add test class to perform functional test:
+> Pre-operation: Create an index (equivalent to a table in MySQL, must exists the table before subsequent CRUD)
+
+```java
+import com.xpc.easyes.core.enums.FieldType;
+@SpringBootTest(classes = EasyEsApplication.class)
+public class SearchTest {
+
+ @Resource
+ DocumentMapper documentMapper;
+
+ @Test
+ public void testCreatIndex() {
+ // Test to create an index If you don’t understand the concept of Es index, please understand it first. A lazy man can be simply understood as a table in MySQL.
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+
+ // For the sake of simplicity, use the class name as the index name directly. The following chapters will teach you how to configure and use the index more flexibly.
+ wrapper.indexName(Document.class.getSimpleName().toLowerCase());
+
+ // Here, the article title is mapped to the keyword type (word segmentation is not supported), and the document content is mapped to the text type (word segmentation query is supported)
+ wrapper.mapping(Document::getTitle, FieldType.KEYWORD)
+ .mapping(Document::getContent, FieldType.TEXT);
+
+ boolean isOk = documentMapper.createIndex(wrapper);
+ Assert.assertTrue(isOk);
+ // Expected value: true If it is true, it proves that the index has been successfully created
+ }
+
+}
+```
+> **Test insert:** Add a new piece of data (equivalent to the Insert operation in MySQL)
+
+```java
+ @Test
+ public void testInsert() {
+ // Test insert data
+ Document document = new Document();
+ document.setTitle("Hello");
+ document.setContent("World");
+ document.setCreator("Guy")
+ String id = documentMapper.insert(document);
+ System.out.println(id);
+ }
+```
+> Test query: query the specified data according to the conditions (equivalent to the Select operation in MySQL)
+
+```java
+ @Test
+ public void testSelect() {
+ // test query
+ String title = "Hello";
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.eq(Document::getTitle,title);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+ Assert.assertEquals(title,document.getTitle());
+ }
+```
+> Test update: update data (equivalent to the Update operation in MySQL)
+
+```java
+ @Test
+ public void testUpdate() {
+ // There are two cases of update, which are demonstrated as follows:
+ // case1: Known id, update according to id (for the convenience of demonstration, this id is copied from the query in the previous step, the actual business can be queried by yourself)
+ String id = "krkvN30BUP1SGucenZQ9";
+ String title1 = "Nice";
+ Document document1 = new Document();
+ document1.setId(id);
+ document1.setTitle(title1);
+ documentMapper.updateById(document1);
+
+ // case2: id unknown, update according to conditions
+ LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
+ wrapper.eq(Document::getTitle,title1);
+ Document document2 = new Document();
+ document2.setTitle("Bad");
+ documentMapper.update(document2,wrapper);
+ }
+```
+Through the update, the data title is first updated to Nice, and finally updated to Bad.
+
+> Test delete: delete data (equivalent to the Delete operation in MySQL)
+
+```java
+ @Test
+ public void testDelete() {
+ // There are two cases for deletion: delete according to id or delete according to conditions
+ // Considering that id deletion is too simple, here is only a demonstration of deletion based on conditions
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "Bad";
+ wrapper.eq(Document::getTitle,title);
+ int successCount = documentMapper.delete(wrapper);
+ System.out.println(successCount);
+ }
+```
+> **TIP**
+> Please move to the complete code sample: [Easy-Es-Sample](https://github.com/xpc1024/easy-es/tree/main/easy-es-sample) (test directory)
+> We are sorry that currently only the Chinese version is provided, but the code itself is the same
+
+## summary
+
+---
+
+Through the above few simple steps, we have realized Document index creation and CRUD function
+
+From the above steps, we can see that integrating Easy-Es is very simple, just import the starter project and configure the mapper scan path.
+
+But the power of Easy-Es is far more than these functions. Want to learn more about the powerful functions of Easy-Es? Then continue browsing!
diff --git a/docs/en/sceen.md b/docs/en/sceen.md
new file mode 100644
index 00000000..7fadbbd2
--- /dev/null
+++ b/docs/en/sceen.md
@@ -0,0 +1,13 @@
+1. Retrieval services
+
+● Search Libraries ● E-commerce product search ● Massive system log retrieval
+
+2. Question-and-answer service (essentially also a retrieval class)
+
+● Online intelligent customer service ● Robots
+
+3. Map services
+
+● Taxi app ● Food delivery app ● Community group purchase and delivery ● Socializing with strangers
+
+... The above are just some application scenarios that I can think of. In fact, the API of Easy-Es basically covers more than 90% of the functions of Elastic Search and more than 99% of the common functions, so you can quickly build various systems based on EE, even if It is a very complex and changeable query, and you can also deal with it calmly, Trust me!
diff --git a/docs/en/select.md b/docs/en/select.md
new file mode 100644
index 00000000..42a6662c
--- /dev/null
+++ b/docs/en/select.md
@@ -0,0 +1,18 @@
+```java
+Long selectCount(LambdaEsQueryWrapper wrapper);
+T selectById(Serializable id);
+List selectBatchIds(Collection idList);
+// According to dynamic query conditions, query a record, if there are multiple records, will throw RuntimeException
+T selectOne(LambdaEsQueryWrapper wrapper);
+// According to the dynamic query conditions, query all the records that meet the conditions
+List selectList(LambdaEsQueryWrapper wrapper);
+```
+**Parameter Description**
+
+| Type | Parameter name | Description |
+| --- | --- | --- |
+| Wrapper | queryWrapper | Query parameter packaging class |
+| Serializable | id | primary key in es |
+| Collection | idList | primary key list in es |
+
+
diff --git a/docs/en/set.md b/docs/en/set.md
new file mode 100644
index 00000000..1ffd0914
--- /dev/null
+++ b/docs/en/set.md
@@ -0,0 +1,5 @@
+```java
+set(String column, Object val)
+set(boolean condition, String column, Object val)
+```
+● SQL SET field ● Example: set(Document::getTitle, "new value") ● Example: set(Document::getTitle, "")--->database field value becomes an empty string ● Example: set(Document::getTitle, null)--->database field value becomes null
diff --git a/docs/en/size.md b/docs/en/size.md
new file mode 100644
index 00000000..0e4f030b
--- /dev/null
+++ b/docs/en/size.md
@@ -0,0 +1,7 @@
+```java
+size(Integer size)
+```
+● How many pieces of data are returned at most, which is equivalent to n in limit (m,n) or n in limit n in MySQL ● Example: size(10)--->Only return 10 pieces of data at most
+> **Tips: **If the size parameter is not specified, its default value is 10000
+> If you do a single query and don't want too much data with low scores, you need to manually specify the size to limit it.
+
diff --git a/docs/en/sort.md b/docs/en/sort.md
new file mode 100644
index 00000000..16459c44
--- /dev/null
+++ b/docs/en/sort.md
@@ -0,0 +1,21 @@
+> For field sorting, ascending sorting and descending sorting are supported:
+
+```java
+wrapper.orderByDesc(Sort fields, support multiple fields)
+wrapper.orderByAsc(Sort fields, support multiple fields)
+```
+Example of use:
+```java
+ @Test
+ public void testSort(){
+ // To test the sorting, we added a creation time field to the Document object, updated the index, and added two pieces of data
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.like(Document::getContent,"Hello");
+ wrapper.select(Document::getTitle,Document::getGmtCreate);
+ List before = documentMapper.selectList(wrapper);
+ System.out.println("before:"+before);
+ wrapper.orderByDesc(Document::getGmtCreate);
+ List desc = documentMapper.selectList(wrapper);
+ System.out.println("desc:"+desc);
+ }
+```
diff --git a/docs/en/source.md b/docs/en/source.md
new file mode 100644
index 00000000..4ca5c74f
--- /dev/null
+++ b/docs/en/source.md
@@ -0,0 +1,7 @@
+```java
+// Get query parameters generated by this framework can be used to check whether the query parameters generated by this framework are correct
+String getSource(LambdaEsQueryWrapper wrapper);
+```
+> **Tips:**
+> The production environment can call this interface before calling the query of this framework, and record the obtained query parameters (JSONString) in the log, so that when a problem occurs, it can be checked whether the query generated by the framework itself has incorrect parameters. Of course, in the later stable version We will discard this method because it is of little significance at present.After a lot of testing, the query parameters generated by the framework have not found any problems.
+
diff --git a/docs/en/update-index.md b/docs/en/update-index.md
new file mode 100644
index 00000000..4ccbd85d
--- /dev/null
+++ b/docs/en/update-index.md
@@ -0,0 +1,17 @@
+In many scenarios, due to changes in the entity model or requirements, we need to update the index. For example, I added an author field creator to the document entity model. At this time, I want to update the index so that it can be based on the author keywords. search
+```java
+ @Test
+ public void testUpdateIndex(){
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ wrapper.indexName(indexName);
+ wrapper.mapping(Document::getCreator,FieldType.KEYWORD);
+ boolean isOk = documentMapper.updateIndex(wrapper);
+ Assert.assertTrue(isOk);
+ }
+```
+> **Tips:**
+> - If your production environment requires a smooth transition, then we do not recommend updating the index in this way, because updating the mapping will cause Es to rebuild the index. In such cases, it is recommended to migrate through the alias method.
+> - indexName cannot be empty, you must specify which index to update
+> - This interface only supports mapping to update the index. If you need to update information such as shards, data sets, index names, etc., it is recommended to call the delete index interface to delete the original index, and then call the index creation interface to re-create the index (low frequency operation, later versions can be based on the user Feedback to decide whether to join the support update)
+
diff --git a/docs/en/update.md b/docs/en/update.md
new file mode 100644
index 00000000..fb60c70d
--- /dev/null
+++ b/docs/en/update.md
@@ -0,0 +1,16 @@
+```java
+Integer updateById(T entity);
+Integer updateBatchByIds(Collection entityList);
+// Update records based on dynamic conditions
+Integer update(T entity, LambdaEsUpdateWrapper updateWrapper);
+```
+**Parameter Description**
+
+| Type | Parameter name | Description |
+| --- | --- | --- |
+| T | entity | The entity that needs to be updated |
+| Wrapper | updateWrapper | Update conditions |
+| Collection | entityList | The entity list that needs to be updated |
+
+
+
diff --git a/docs/en/weight.md b/docs/en/weight.md
new file mode 100644
index 00000000..00019f12
--- /dev/null
+++ b/docs/en/weight.md
@@ -0,0 +1,23 @@
+> The weight query is also a query that Es has and MySQL does not have, and the syntax is as follows
+
+```java
+function(field, value, Float weightsValue)
+```
+```java
+ @Test
+ public void testWeight() throws IOException {
+ // 测试权重
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "Hello";
+ float contentBoost = 5.0f;
+ wrapper.match(Document::getContent,keyword,contentBoost);
+ String creator = "Guy";
+ float creatorBoost = 2.0f;
+ wrapper.eq(Document::getCreator,creator,creatorBoost);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> Tips:
+> If you need a score, you can return it through SearchResponse. If you don't need a score, you only need to return it according to the ranking with the highest score, and you can directly use List to receive it.
+
diff --git a/docs/en/worry-free.md b/docs/en/worry-free.md
new file mode 100644
index 00000000..c2c47555
--- /dev/null
+++ b/docs/en/worry-free.md
@@ -0,0 +1,77 @@
+# 1.Performance
+
+---
+
+Before formally connecting Easy-Es to the production environment, you will definitely worry about a question, that is, after using this framework, will the query efficiency of the system decrease? Will the system resource overhead increase? How much is the negative impact?
+
+These problems are related to the survival of a framework. As an EE author, I have considered these problems before development, but users do not know, so I will help you to crush these concerns one by one.
+
+
+
+Let's first look at what EE does in the entire query process? To sum up, there are 2 things:
+
+1. Convert the MySQL syntax (Mybatis-Plus syntax) entered by the user into RestHighLevel syntax, and then call RestHighLevelClient to execute the query
+1. Convert the query result into the format the user wants: such as List and return it.
+
+● Among them, the syntax conversion is performed according to the relationship between the EE and RestHighLevelClient syntax comparison table. This conversion actually consumes very low performance, because even if you use RestHighLevelClient to query directly, you still need to create termQueryBuilder and BoolQueryBuilder. The only difference is I put the query conditions eq entered by the user into the queue, and then convert them one by one in the order of the FIFO in the queue (except when there is an or in the query conditions). For most query statements, there are not too many query conditions, so The number of elements in the queue will be less than 10 in most cases, and I only store enumerations and parameters in the queue, which will neither take up too much memory nor consume much performance due to the traversal of the queue. For modern computers , let alone traversing 10 small pieces of data, even hundreds or thousands of pieces of data are in milliseconds, so this performance loss is basically negligible.
+
+● Let’s talk about the result parsing. The result parsing is actually to take out the hits in the SearchResponse returned by calling RestHighLevelClient and convert it into an array with fastJson. Even if you don’t need EE, you will still have this step if you use RestHighLevelClient directly, so there is not too much loss in this step. , even if I use reflection, the reflection and annotation information of the field are loaded into the memory when the framework starts, and the jvm cache is done, so this loss is negligible.
+
+Of course, the above are all based on theoretical analysis. In version 0.9.6, in the Performance test class of the test directory of the Sample module, you can see that I have made performance tests of different dimensions for CURD, and the actual test results are also very good. Based on my theoretical analysis above, EE is 10-15 milliseconds slower on average than using RestHighLevelClient directly, and there is no difference in adding, deleting or modifying the API, and with the increase in the amount of query data, after the entity field cache takes effect, the query difference will be further reduced. , almost negligible. Sacrificing 10 milliseconds is imperceptible to users, but for development, it can save a lot of code and time, I think it's worth it, basically no ORM framework is not depleted Performance, weighing the pros and cons, the protagonists should have the answer psychologically.
+
+# 2.Safety
+
+---
+
+
+The bottom layer of EE is the RestHighLevelClient officially provided by Es. We only enhanced RestHighLevelClient, and did not change or weaken its original functions, so you don't need to worry about scalability.
+
+The use of any framework will reduce the flexibility of the system, because the framework is dead. After using it, you will inevitably encounter some scenarios that cannot be satisfied by the framework, which requires customized development, or you do not understand the framework itself in the short term, so dare not rashly. Use it, otherwise what should I do if I encounter problems in the future?
+
+In order to solve the above problems, I specially left [hybrid query](/en/hybrid-query.md) and [native query](/en/origin-query.md) in the framework
+
+At present, all APIs provided by EE can cover 99% of the actual development requirements. When 1% of the requirements cannot be covered in a very small probability, you can use hybrid query, that is, the statements that can be supported are generated by EE, and the statements that cannot be supported can be generated by EE. Just use the syntax of RestHighLevelClient directly, and then complete the query through the native interface, which is simple and hassle-free. Of course, if you don't like this "hybrid oil-electricity" method, you can also directly use the native query interface to complete the query, and directly Same as using RestHighLevelClient.
+
+Of course, if you really don't want to use any of the methods provided by EE, EE can still be used as an auto-configured version of RestHighLevelClient. You can directly inject RestHighLevelClient where you need it for use. EE has already helped you configure RestHighLevelClient as you specified in the configuration file. , is automatically assembled into SpringBean, so in any case, you can be very confident and calm, just like using the official RestHighLevelClient directly, you don't need to worry about what to do if there is a problem one day, don't use EE, just treat it as a A tool that introduces dependencies and automatic configuration. And this possibility is very low. We also have a dedicated Q&A group to give you free online support, and will respond to your reasonable needs as soon as possible and arrange the landing.
+
+# 3.Expandability
+
+---
+
+The bottom layer of EE is the RestHighLevelClient officially provided by Es. We only enhanced RestHighLevelClient, and did not change or weaken its original functions, so you don't need to worry about scalability.
+
+The use of any framework will reduce the flexibility of the system, because the framework is dead. After using it, it will inevitably encounter some scenarios that the framework cannot satisfy, and need to be customized. Use it, otherwise what should I do if I encounter problems in the future?
+
+In order to solve the above problems, I specially left semi-native queries and full-native queries in the framework
+
+At present, all APIs provided by EE can cover 99% of the actual development requirements. When 1% of the requirements cannot be covered in a very small probability, you can use semi-native queries, that is, the supported statements are generated by EE, and the unsupported statements are generated by EE. The statement directly uses the syntax of RestHighLevelClient, and then completes the query through the semi-native interface, which is simple and hassle-free. Of course, if you do not like this "hybrid" method, you can also directly use the native query interface to complete the query. Same as using RestHighLevelClient directly.
+
+Of course, if you really don't want to use any of the methods provided by EE, EE can still be used as an auto-configured version of RestHighLevelClient. You can directly inject RestHighLevelClient where you need it for use. EE has already helped you configure RestHighLevelClient as you specified in the configuration file. , is automatically assembled into SpringBean, so in any case, you can be confident and calm, just like using the official RestHighLevelClient directly, you don't need to worry about what to do if something goes wrong one day, don't use EE, just treat it as a A tool that introduces dependencies and automatic configuration. And this possibility is very low. We also have a dedicated Q&A group to give you free online support, and will respond to your reasonable needs as soon as possible and arrange the landing.
+
+# 4.Team and community activity
+
+---
+
+The team has recruited 5 people, which I call "General Five Tigers". TeamWork has been started since version 0.9.5+. In the future, as the project develops, more people with lofty ideals will be recruited. The community is currently active and will meet every year. Release many versions to continuously improve the user experience. We will respond to the needs of users within a week. If it is reasonable, the project will be established within one month, and the development and launch will be completed within three months. Issues will be resolved within two weeks after confirmation. online.
+
+# 5.Access advantages
+
+---
+
+● Simple, easy to use and efficient, I don't need to say more, MyBatis-Plus users know everything! Save a lot of time, make love...do things, really fragrant!
+
+● The use threshold is lowered, even a novice who just doesn't understand Es can use EE to develop various functions
+
+● Significantly reduce the amount of code, improve code readability, reduce the amount of repetitive code, and improve code quality
+
+● Professional Q&A team, worry-free after-sales
+
+● Free forever
+
+...
+
+# 6.Conclusion
+
+---
+
+When the new energy vehicle first came out, the owners of the gas truck were still waiting and watching. Those who got on the car first had already experienced the sweetness. You will know if it is good or not. As for those so-called problems, they will be solved with time. Try new things more, Only by embracing change, not conforming to the old ways, and looking at the ever-changing world without immutable concepts, can you be invincible.
diff --git a/docs/eq.md b/docs/eq.md
new file mode 100644
index 00000000..f016db41
--- /dev/null
+++ b/docs/eq.md
@@ -0,0 +1,7 @@
+```java
+eq(R column, Object val)
+eq(boolean condition, R column, Object val)
+```
+
+- 等于 =
+- 例: eq("name", "老王")--->name = '老王'
diff --git a/docs/exists-index.md b/docs/exists-index.md
new file mode 100644
index 00000000..b7ad6d8e
--- /dev/null
+++ b/docs/exists-index.md
@@ -0,0 +1,11 @@
+> 可用于校验是否存在名称为指定名称的索引
+
+```java
+ @Test
+ public void testExistsIndex(){
+ // 测试是否存在指定名称的索引
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ boolean existsIndex = documentMapper.existsIndex(indexName);
+ Assert.assertTrue(existsIndex);
+ }
+```
diff --git a/docs/faq.md b/docs/faq.md
new file mode 100644
index 00000000..a10a87af
--- /dev/null
+++ b/docs/faq.md
@@ -0,0 +1,37 @@
+1.当碰到有一些需求EE提供的API不支持时怎么办? 没关系,作者早就帮主公们想到最优的解决方案了,请查看这里:[混合查询](hybrid-query.md)
+
+2.试用过程中,报错:java.lang.reflect.UndeclaredThrowableException
+```
+Caused by: [daily_document] ElasticsearchStatusException[Elasticsearch exception [type=index_not_found_exception, reason=no such index [daily_document]]]
+```
+如果您的错误信息和原因与上面一致,请检查索引名称是否正确配置,检查全局配置,注解配置,如果配置无误,可能是索引不存在,您可以通过es-head可视化工具查看是否已存在指定索引,若无此索引,可以通过EE提供的API快速创建.
+
+3.依赖冲突 尽管EE框架足够轻量,我在研发过程中也尽量避免使用过多其它依赖,但仍难保证在极小概率下发生和宿主项目发生依赖冲突的情况,如果有依赖冲突,开发者可通过移除重复依赖或统一依赖版本号来解决,EE所有可能发生冲突的依赖如下:
+```xml
+
+ org.projectlombok
+ lombok
+ 1.18.12
+
+
+ org.elasticsearch.client
+ elasticsearch-rest-high-level-client
+ 7.10.1
+
+
+ org.elasticsearch
+ elasticsearch
+ 7.10.1
+
+
+ com.alibaba
+ fastjson
+ 1.2.79
+
+
+ commons-codec
+ commons-codec
+ 1.6
+
+```
+
diff --git a/docs/field-anno.md b/docs/field-anno.md
new file mode 100644
index 00000000..3458d2b8
--- /dev/null
+++ b/docs/field-anno.md
@@ -0,0 +1,27 @@
+字段注解@TableField功能和MP一致,但相比MP针对一些低频使用功能做了一些阉割,后续根据用户反馈可随迭代逐步加入,目前版本目前只支持以下两种场景:
+
+1. 实体类中的字段并非ES中实际的字段,比如把实体类直接当DTO用了,加了一些ES中并不存在的无关字段,此时可以标记此字段,以便让EE框架跳过此字段,对此字段不处理.
+1. 字段的更新策略,比如在调用更新接口时,实体类的字段非Null或者非空字符串时才更新,此时可以加字段注解,对指定字段标记更新策略.
+
+使用示例:
+```java
+ public class Document {
+ // 此处省略其它字段...
+
+ // 场景一:标记es中不存在的字段
+ @TableField(exist = false)
+ private String notExistsField;
+
+ // 场景二:更新时,此字段非空字符串才会被更新
+ @TableField(strategy = FieldStrategy.NOT_EMPTY)
+ private String creator;
+ }
+```
+> **Tips:**
+> - 更新策略一共有3种:
+>
+NOT_NULL: 非Null判断,字段值为非Null时,才会被更新
+> NOT_EMPTY: 非空判断,字段值为非空字符串时才会被更新
+> IGNORE: 忽略判断,无论字段值为什么,都会被更新
+> - 优先级: 字段注解中指定的更新策略>全局配置中指定的更新策略
+
diff --git a/docs/filter.md b/docs/filter.md
new file mode 100644
index 00000000..6dd27e86
--- /dev/null
+++ b/docs/filter.md
@@ -0,0 +1,38 @@
+如果您在某些查询中,不想查一些大字段,您可以过滤查询的字段
+
+1. 正向过滤(只查询指定字段)
+```java
+ @Test
+ public void testFilterField() {
+ // 测试只查询指定字段
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "老汉";
+ wrapper.eq(Document::getTitle, title);
+ wrapper.select(Document::getTitle);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+ }
+```
+
+2. 反向过滤(不查询指定字段)
+```java
+ @Test
+ public void testNotFilterField() {
+ // 测试不查询指定字段 (推荐)
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "老汉";
+ wrapper.eq(Document::getTitle, title);
+ wrapper.notSelect(Document::getTitle);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+
+ // 另外一种与mp一致语法的Lambda写法
+ LambdaEsQueryWrapper wrapper1 = new LambdaEsQueryWrapper<>();
+ wrapper1.select(Document.class, d -> !Objects.equals(d.getColumn(), "title"));
+ Document document1 = documentMapper.selectOne(wrapper);
+ System.out.println(document1);
+ }
+```
+> **Tips:**
+> 正向过滤和反向过滤你只能选择其中一种,如果同时使用两种过滤规则,会导致冲突字段失去过滤效果.
+
diff --git a/docs/from.md b/docs/from.md
new file mode 100644
index 00000000..290c46fc
--- /dev/null
+++ b/docs/from.md
@@ -0,0 +1,6 @@
+```java
+from(Integer from)
+```
+
+- 从第几条数据开始查询,相当于MySQL中limit (m,n)中的m.
+- 例: from(10)--->从第10条数据开始查询
diff --git a/docs/ge.md b/docs/ge.md
new file mode 100644
index 00000000..4bc168fe
--- /dev/null
+++ b/docs/ge.md
@@ -0,0 +1,7 @@
+```java
+ge(R column, Object val)
+ge(boolean condition, R column, Object val)
+```
+
+- 大于等于 >=
+- 例: ge("age", 18)--->age >= 18
diff --git a/docs/geo-bounding-box.md b/docs/geo-bounding-box.md
new file mode 100644
index 00000000..775a6251
--- /dev/null
+++ b/docs/geo-bounding-box.md
@@ -0,0 +1,44 @@
+GeoBoundingBox: 直译为地理边界盒,由左上点和右下点构成的矩形范围,在此范围内的点均可以被查询出来,实际使用的并不多,可参考下图: 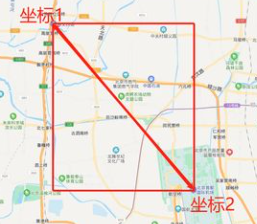
+
+API:
+
+```java
+geoBoundingBox(R column, GeoPoint topLeft, GeoPoint bottomRight)
+```
+使用示例:
+```java
+@Test
+ public void testGeoBoundingBox() {
+ // 查询位于左上点和右下点坐标构成的长方形内的所有点
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // 假设左上点坐标
+ GeoPoint leftTop = new GeoPoint(41.187328D, 115.498353D);
+ // 假设右下点坐标
+ GeoPoint bottomRight = new GeoPoint(39.084509D, 117.610461D);
+ wrapper.geoBoundingBox(Document::getLocation, leftTop, bottomRight);
+ List documents = documentMapper.selectList(wrapper);
+ documents.forEach(System.out::println);
+ }
+```
+> **Tips:**
+> 1. 上面使用示例仅演示了其中一种,实际上本框架中坐标点的语法支持非常多种,ElasticSearch官方提供的几种数据格式都支持,用户可按自己习惯自行选择对应的api进行查询参数构造:
+> - **GeoPoint:上面Demo中使用的经纬度表示方式**
+> - **经纬度数组 :**[116.498353, 40.187328],[116.610461, 40.084509]
+> - **经纬度字符串:**"40.187328, 116.498353","116.610461, 40.084509
+> - **经纬度边界框WKT:**"BBOX (116.498353,116.610461,40.187328,40.084509)"
+> - **经纬度GeoHash(哈希):**"xxx"
+>
+ 其中,经纬度哈希的转换可参考此网站:[GeoHash坐标在线转换](http://geohash.co/)
+>
+> 2. 字段的索引类型必须为geoPoint,否则相关查询API失效,可参考下图.
+> 2. 字段类型推荐使用String,因为wkt文本格式就是String,非常方便,至于字段名称,见名知意即可.
+
+
+
+
+```java
+public class Document {
+ // 省略其它字段...
+ private String location;
+}
+```
diff --git a/docs/geo-distance.md b/docs/geo-distance.md
new file mode 100644
index 00000000..b3e97901
--- /dev/null
+++ b/docs/geo-distance.md
@@ -0,0 +1,30 @@
+GeoDistance:直译为地理距离,实际上就是以给定的点为圆心,给定的半径画个圆,处在此圆内的点都能被查出来,使用较为高频,比如像我们用的外卖软件,查询周围3公里内的所有店铺,就可以用此功能去实现,没错你还可以用来写YP软件,查询下附近三公里内的PLMM...
+
+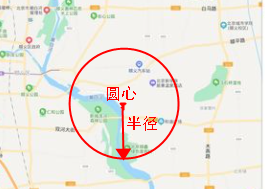
+
+API:
+
+```java
+geoDistance(R column, Double distance, DistanceUnit distanceUnit, GeoPoint centralGeoPoint)
+```
+使用示例:
+```java
+ @Test
+ public void testGeoDistance() {
+ // 查询以经度为41.0,纬度为115.0为圆心,半径168.8公里内的所有点
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // 其中单位可以省略,默认为km
+ wrapper.geoDistance(Document::getLocation, 168.8, DistanceUnit.KILOMETERS, new GeoPoint(41.0, 116.0));
+ // 上面语法也可以写成下面这几种形式,效果是一样的,兼容不同用户习惯而已:
+// wrapper.geoDistance(Document::getLocation,"1.5km",new GeoPoint(41.0,115.0));
+// wrapper.geoDistance(Document::getLocation, "1.5km", "41.0,115.0");
+
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+> **Tips:**
+> 1. 同样的对于坐标点的表达形式也支持多种,和GeoBondingBox中的Tips介绍的一样,这里不再赘述.
+> 1. 索引类型和字段类型与GeoBondingBox中的Tips介绍的一样
+> 1. 对于宠粉的EE来说,兼容各种用户的不同习惯是理所当然的,所以你在使用时会发现大量方法重载,选一种最符合你使用习惯或符合指定使用场景的api进行调用即可.
+
diff --git a/docs/geo-ploygon.md b/docs/geo-ploygon.md
new file mode 100644
index 00000000..a68de96b
--- /dev/null
+++ b/docs/geo-ploygon.md
@@ -0,0 +1,31 @@
+GeoPolygon:直译为地理多边形,实际上就是以给定的所有点构成的多边形为范围,查询此范围内的所有点,此功能常被用来做电子围栏,使用也较为高频,像共享单车可以停放的区域就可以通过此技术实现,可参考下图:
+
+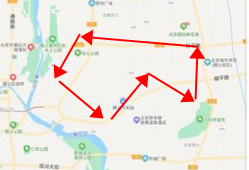
+
+API:
+```java
+geoPolygon(R column, List geoPoints)
+```
+使用示例:
+```java
+ @Test
+ public void testGeoPolygon() {
+ // 查询以给定点列表构成的不规则图形内的所有点,点数至少为3个
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ List geoPoints = new ArrayList<>();
+ GeoPoint geoPoint = new GeoPoint(40.178012, 116.577188);
+ GeoPoint geoPoint1 = new GeoPoint(40.169329, 116.586315);
+ GeoPoint geoPoint2 = new GeoPoint(40.178288, 116.591813);
+ geoPoints.add(geoPoint);
+ geoPoints.add(geoPoint1);
+ geoPoints.add(geoPoint2);
+ wrapper.geoPolygon(Document::getLocation, geoPoints);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+> **Tips:**
+> 1. 同样的,关于坐标点的入参形式,也支持多种,与官方一致,可以参考GeoBoundingBox中的Tips,这里不赘述.值得注意的是多边形的点数不能少于3个,否则Es无法勾勒出多边形,本次查询会报错.
+> 1. 索引类型和字段类型与GeoBondingBox中的Tips介绍的一样
+
+
diff --git a/docs/geo-polygon.md b/docs/geo-polygon.md
new file mode 100644
index 00000000..4140023b
--- /dev/null
+++ b/docs/geo-polygon.md
@@ -0,0 +1,27 @@
+GeoPolygon:直译为地理多边形,实际上就是以给定的所有点构成的多边形为范围,查询此范围内的所有点,此功能常被用来做电子围栏,使用也较为高频,像共享单车可以停放的区域就可以通过此技术实现,可参考下图: 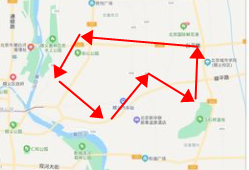 API:
+```java
+geoPolygon(R column, List geoPoints)
+```
+使用示例:
+```java
+ @Test
+ public void testGeoPolygon() {
+ // 查询以给定点列表构成的不规则图形内的所有点,点数至少为3个
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ List geoPoints = new ArrayList<>();
+ GeoPoint geoPoint = new GeoPoint(40.178012, 116.577188);
+ GeoPoint geoPoint1 = new GeoPoint(40.169329, 116.586315);
+ GeoPoint geoPoint2 = new GeoPoint(40.178288, 116.591813);
+ geoPoints.add(geoPoint);
+ geoPoints.add(geoPoint1);
+ geoPoints.add(geoPoint2);
+ wrapper.geoPolygon(Document::getLocation, geoPoints);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+> **Tips:**
+> 1. 同样的,关于坐标点的入参形式,也支持多种,与官方一致,可以参考GeoBoundingBox中的Tips,这里不赘述.值得注意的是多边形的点数不能少于3个,否则Es无法勾勒出多边形,本次查询会报错.
+> 1. 索引类型和字段类型与GeoBondingBox中的Tips介绍的一样
+
+
diff --git a/docs/geo-shape.md b/docs/geo-shape.md
new file mode 100644
index 00000000..27733d0e
--- /dev/null
+++ b/docs/geo-shape.md
@@ -0,0 +1,67 @@
+GeoShape:直译为地理图形,怎么理解?乍一看好像和GeoPolygon很像,但实际上,前面三种类型查询的都是坐标点,而此方法查询的是图形,比如一个园区,从世界地图上看可以把它当做一个点,但如果放得足够大,比如把地图具体到杭州市滨江区,园区就可能变成若干个点构成的一个区域,在一些特殊的场景中,需要查询此完整的区域,以及两个区域的交集之类的,就需要用到GeoShape了,如果你还不理解,不妨先接着往下看,以杭州为例,我举一个健康码的例子,假设黑色圈内区域为中风险地区,我现在要查出ES中所有在市民中心且处于中风险区域的人,把他们的健康码统统变成橙色,那实际上我要找的就是下图中橙色那块区域,此时红色箭头所构成的区域是整个市民中心,我可以把整个市民中心作为一个地理图形,然后把黑色大圆作为查询的图形,找出它们的交集即可.
+
+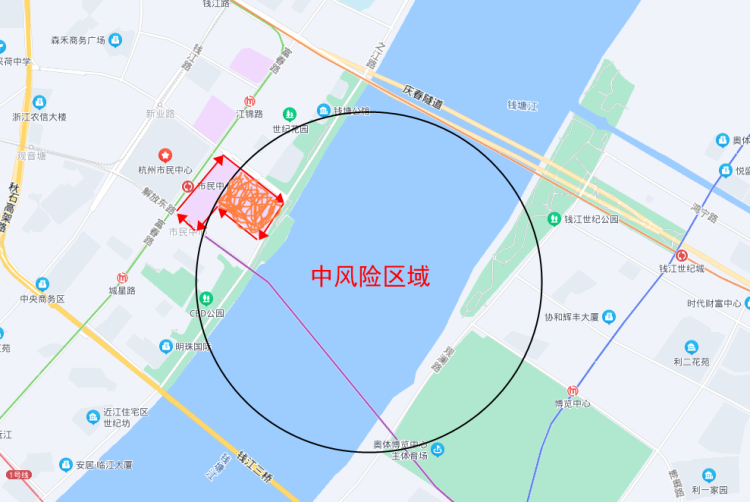
+
+上图对应的ShapeRelation为INTERSECTS,看以看下面API.
+
+API:
+```java
+geoShape(R column, String indexedShapeId);
+
+geoShape(R column, Geometry geometry, ShapeRelation shapeRelation);
+```
+使用示例:
+
+此API不常用,也可直接跳过看下面通过图形查询的.
+```java
+ /**
+ * 已知图形索引ID(不常用)
+ * 在一些高频场景下,比如一个已经造好的园区,其图形坐标是固定的,因此可以先把这种固定的图形先存进es
+ * 后续可根据此图形的id直接查询,比较方便,故有此方法,但不够灵活,不常用
+ */
+ @Test
+ public void testGeoShapeWithShapeId() {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // 这里的indexedShapeId为用户事先已经在Es中创建好的图形的id
+ wrapper.geoShape(Document::getGeoLocation, "edu");
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+此API相较上面方式更常用,即用户可以自行指定要查询的图形是矩形,圆形,还是多边形...(具体看代码中注释):
+```java
+ /**
+ * 图形由用户自定义(常用),本框架支持Es所有支持的图形:
+ * (Point,MultiPoint,Line,MultiLine,Circle,LineaRing,Polygon,MultiPolygon,Rectangle)
+ */
+ @Test
+ public void testGeoShape() {
+ // 注意,这里查询的是图形,所以图形的字段索引类型必须为geoShape,不能为geoPoint,故这里用geoLocation字段而非location字段
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ // 这里以矩形为例演示,其中x,y为圆心坐标,r为半径. 其它图形请读者自行演示,篇幅原因不一一演示了
+ Circle circle = new Circle(13,14,100);
+ // shapeRelation支持多种,如果不传则默认为within
+ wrapper.geoShape(Document::getGeoLocation, circle, ShapeRelation.INTERSECTS);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
+上述地图中的
+市民中心(多边形)的WKT(Well-Known Text)坐标(模拟的数据,真实数据可从高德地图/百度地图等通过 调用它们提供的开放API获取):
+
+"POLYGON((108.36549282073975 22.797566864832092,108.35974216461182 22.786093175673713,108.37265968322754 22.775963875498206,108.4035587310791 22.77600344454008,108.41003894805907 22.787557113881462,108.39557647705077 22.805360509802284,108.36549282073975 22.797566864832092))";
+
+已经存储在Es中了,实际上我们在项目中都会把可能用到的数据或业务数据都事先存入Es了,否则查询也就无意义了,查个空气? 所以上面API根据GeoShape查询时,需要传入的参数的仅是你圈定的范围的图形(上面该参数是圆).
+
+> **TIps:**
+> - GeoShape容易和GeoPolygon混淆,需要特别注意,它俩其实是两种不同的东西.
+> - GeoShape进行查询的字段索引类型必须是geo_shape类型,否则此API无法使用,参考下图
+> - 字段类型推荐使用String,因为wkt文本格式就是String,非常方便,至于字段名称,见名知意即可.
+
+
+```java
+public class Document {
+ // 省略其它字段...
+ private String geoLocation;
+}
+```
diff --git a/docs/geo.md b/docs/geo.md
new file mode 100644
index 00000000..b9b7e84a
--- /dev/null
+++ b/docs/geo.md
@@ -0,0 +1,35 @@
+> 支持版本:0.9.5+
+> 地理位置查询,与Es官方提供的功能完全一致,共支持4种类型的地理位置查询:
+> - GeoBoundingBox
+> - GeoDistance
+> - GeoPolygon
+> - GeoShape
+>
+通过这4类查询,可以实现各种强大实用的功能
+
+应用场景:
+
+- 外卖类APP 附近的门店
+- 社交类APP 附近的人
+- 打车类APP 附近的司机
+- 区域人群画像类APP 指定范围内的人群特征提取
+- 健康码等
+- ...
+
+功能覆盖100%,且使用更为简单,4类查询的详细介绍请点击左侧菜单进入子项进行查看
+> **Tips:**
+> 1. 在使用地理位置查询API之前,需要提前创建或更新好索引
+> - 其中前三类API(GeoBoundingBox,GeoDistance,GeoPolygon)字段索引类型必须为geo_point
+> - GeoShape字段索引类型必须为geo_shape,具体可参考下图
+>
+> 2. 字段类型推荐使用String,因为wkt文本格式就是String,非常方便,至于字段名称,见名知意即可.
+>
+
+
+```java
+public class Document {
+ // 省略其它字段...
+ private String location;
+ private String geoLocation;
+}
+```
diff --git a/docs/groupBy.md b/docs/groupBy.md
new file mode 100644
index 00000000..b7371d3b
--- /dev/null
+++ b/docs/groupBy.md
@@ -0,0 +1,7 @@
+```java
+groupBy(R... columns)
+groupBy(boolean condition, R... columns)
+```
+
+- 分组:GROUP BY 字段, ...
+- 例: groupBy(Document::getId,Document::getTitle)--->group by id,title
diff --git a/docs/gt.md b/docs/gt.md
new file mode 100644
index 00000000..bf3213a1
--- /dev/null
+++ b/docs/gt.md
@@ -0,0 +1,7 @@
+```java
+gt(R column, Object val)
+gt(boolean condition, R column, Object val)
+```
+
+- 大于 >
+- 例: gt("age", 18)--->age > 18
diff --git a/docs/highlight.md b/docs/highlight.md
new file mode 100644
index 00000000..cb826b80
--- /dev/null
+++ b/docs/highlight.md
@@ -0,0 +1,23 @@
+语法:
+```java
+// 不指定高亮标签,默认采用返回高亮内容
+highLight(高亮字段);
+// 指定高亮标签
+highLight(高亮字段,开始标签,结束标签)
+```
+```java
+ @Test
+ public void testHighlight() throws IOException {
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "过硬";
+ wrapper.match(Document::getContent,keyword);
+ wrapper.highLight(Document::getContent);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> **Tips:**
+> - 如果需要多字段高亮,则字段与字段之间可以用逗号隔开
+> - 必须使用SearchResponse接收,否则返回体中无高亮字段
+>
+
diff --git a/docs/hybrid-query.md b/docs/hybrid-query.md
new file mode 100644
index 00000000..9e43f8f7
--- /dev/null
+++ b/docs/hybrid-query.md
@@ -0,0 +1,48 @@
+# 何为混合查询?
+简单理解,就是一半采用EE的语法,一半采用RestHighLevelClient的语法,类似"油电混动",相信你会爱上这种"油电混动"模式,因为它结合了两种模式的优点!
+# 为什么要有混合查询?
+因为EE目前还没有做到对RestHighLevelClient的功能100%覆盖,目前开源初期,仅覆盖了RestHighLevelClient约90%左右的功能,99%的核心高频使用功能,如此就不可避免的会出现个别场景下,EE不能满足某个特殊需求,此时对EE框架进行二次开发或直接将该需求提给EE作者,在时间上都无法满足开发者需求,有些需求可能产品经理要的比较紧,那么此时,您就可以通过混合查询来解决窘境.
+# 如何使用混合查询?
+在我没提供此篇文档时,尽管我提供了混合查询的API和简单介绍,但很多人还不知道有此功能,更不知道该如何使用,所以这里我以一个具体的案例,给大家演示如何使用混合查询,供大家参考,主公们别担心篇幅多,其实非常非常简单,只是我教程写的细.
+
+> **背景:** 用户"向阳"微信向我反馈,说目前EE尚不支持查询按照距给定点的位置由近及远排序.
+> 实际开发中,此场景可以被应用到打车时"乘客下单,要求优先派单给周围3公里内离我最近的司机",然后该乘客是个美女,担心自身安全问题,又多加了几个要求,比如司机必须是女性,驾龄大于3年,商务型车子等...
+
+
+以上面打车的场景为例,我们来看下用EE怎么查询?上面查询可以分为两部分
+
+- EE支持的常规查询:如周围3公里内,司机性别为女,查询驾龄>=3年...
+- EE不支持的非常规查询:按照复杂的排序规则排序(目前EE仅支持常规字段的升序/降序排序)
+
+对于支持的部分,我们可以直接调用EE,由EE先构建一个SearchSourceBuilder出来
+```java
+// 假设该乘客所在位置经纬度为 31.256224D, 121.462311D
+LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+wrapper.geoDistance(Driver::getLocation, 3.0, DistanceUnit.KILOMETERS, new GeoPoint(31.256224D, 121.462311D));
+ .eq(Driver::getGender,"女"")
+ .ge(Driver::getDriverAge,3)
+ .eq(Driver::getCarModel,"商务车");
+SearchSourceBuilder searchSourceBuilder = driverMapper.getSearchSourceBuilder(wrapper);
+```
+对于不支持的语句,可以继续用RestHighLevelClient的语法进行封装,封装好了,直接调用EE提供的原生查询接口,就可以完成整个查询.
+```java
+SearchRequest searchRequest = new SearchRequest("索引名");
+// 此处的searchSourceBuilder由上面EE构建而来,我们继续对其追加排序参数
+searchSourceBuilder.sort(
+ new GeoDistanceSortBuilder("location", 31.256224D, 121.462311D)
+ .order(SortOrder.DESC)
+ .unit(DistanceUnit.KILOMETERS)
+ .geoDistance(GeoDistance.ARC)
+);
+searchRequest.source(searchSourceBuilder);
+SearchResponse searchResponse = driverMapper.search(searchRequest, RequestOptions.DEFAULT);
+```
+
+ 如此您便可以既享受到了EE帮您生成好的基本查询,又可完成EE暂未支持的功能,只需要不太多的代码(相比直接RestHighLevelClient,仍能节省大量代码)就可以达成您的目标,和当下纯电动汽车尚未完全发展成熟下的一种折中方案---油电混动有着异曲同工之妙.
+
+当然,如果您不习惯使用这种模式,您仍可以直接使用原生查询,所以您大可以无忧无虑的使用EE,我们已经为您想好了各种兜底的方案和退路,无忧售后!如果您也认可这种模式,不妨给作者点个赞吧,为了让EE的用户爽,作者那糟老头子可谓是煞费苦心!
+
+# 结语
+
+因为ES官方提供的RestHighLevel支持的功能实在是过于繁多,尽管我目前仍在马不停蹄的集成各种新的功能,以及修复用户反馈的问题,优化既有代码性能,但仍不可避免地会出现有些许功能不能满足您当前需求,请各位主公们见谅,EE才诞生三个月,不可能做到十全十美,请给我们一点时间,这些所谓的不足,都会被解决,就像新能源车在未来终会逐步取代燃油车,那些所谓的问题,在未来都不是问题,乌拉!
+
diff --git a/docs/id-anno.md b/docs/id-anno.md
new file mode 100644
index 00000000..957576b6
--- /dev/null
+++ b/docs/id-anno.md
@@ -0,0 +1,25 @@
+主键注解@TableId功能和MP一致,但相比MP针对一些低频使用功能做了一些阉割,后续根据用户反馈可随迭代逐步加入,目前版本目前只支持以下两种场景:
+
+1. 对es中的唯一id进行重命名
+1. 指定es中的唯一id生成方式
+
+示例:
+```java
+public class Document {
+ /**
+ * es中的唯一id
+ */
+ @TableId(value = "myId",type = IdType.AUTO)
+ private String id;
+
+ // 省略其它字段...
+}
+```
+> **Tips:**
+> - **由于es对id的默认名称做了处理(下划线+id):_id,所以EE已为您屏蔽这步操作,您无需在注解中指定,框架也会自动帮您完成映射.**
+> - **Id的生成类型支持以下几种:**
+> - **IdType.AUTO:** 由ES自动生成,是默认的配置,无需您额外配置 推荐
+> - **IdType.UUID:** 系统生成UUID,然后插入ES (不推荐)
+> - **IdType.CUSTOMIZE:** (版本号>=0.9.6支持)由用户自定义,用户自己对id值进行set,如果用户指定的id在es中不存在,则在insert时就会新增一条记录,如果用户指定的id在es中已存在记录,则自动更新该id对应的记录.
+> - **优先级:** 注解配置的Id生成策略>全局配置的Id生成策略
+
diff --git a/docs/in.md b/docs/in.md
new file mode 100644
index 00000000..8227ab24
--- /dev/null
+++ b/docs/in.md
@@ -0,0 +1,14 @@
+```java
+in(R column, Collection value)
+in(boolean condition, R column, Collection value)
+```
+
+- 字段 in (value.get(0), value.get(1), ...)
+- 例: in("age",{1,2,3})--->age in (1,2,3)
+```java
+in(R column, Object... values)
+in(boolean condition, R column, Object... values)
+```
+
+- 字段 in (v0, v1, ...)
+- 例: in("age", 1, 2, 3)--->age in (1,2,3)
diff --git a/docs/index-alias.md b/docs/index-alias.md
new file mode 100644
index 00000000..cc2336b4
--- /dev/null
+++ b/docs/index-alias.md
@@ -0,0 +1,9 @@
+```java
+/**
+ * 设置别名信息
+ * @param aliasName
+ */
+createAlias(String aliasName)
+```
+
+>**Tip:** 无论您目前是否会使用别名,我们都强烈建议您在生产环境创建索引时给该索引取一个有意义的别名,这样未来如果您有索引变更计划时,可以通过别名平滑过渡,不影响生产环境的服务,可通过别名平滑迁移,迁移过程如失败,可轻松完成回滚.
\ No newline at end of file
diff --git a/docs/index-anno.md b/docs/index-anno.md
new file mode 100644
index 00000000..2d38d87c
--- /dev/null
+++ b/docs/index-anno.md
@@ -0,0 +1,14 @@
+索引如果用户不配置,也不指定注解,则采用模型名称的小写字母作为索引,例如模型叫Document,那么索引就为document. 我们同样也支持根据@TableName注解进行指定索引名称,为了保持和MP一样的语法,这里注解命名暂时先保持@TableName,但实际上代表的是索引名称. 使用示例:假设我的索引名称叫: daily_document,那么我们可以在模型上加上此注解
+```java
+@TableName("daily_document")
+public class Document {
+ ...
+}
+```
+> **Tips:**
+> - 通过注解指定的索引名称优先级最高,指定了注解索引,则全局配置和自动生成索引不生效,采用注解中指定的索引名称. 优先级排序: 注解索引>全局配置索引前缀>自动生成
+> - keepGlobalPrefix选项,(0.9.4+版本才支持)默认值为false,是否保持使用全局的 tablePrefix 的值:
+> - 既配置了全局tablePrefix,@TableName注解又指定了value值时,此注解选项才会生效,如果其值为true,则框架最终使用的索引名称为:全局tablePrefix+此注解的value,例如:dev_document.
+> - 此注解选项卡用法和MP中保持一致.
+>
+
diff --git a/docs/index-shard.md b/docs/index-shard.md
new file mode 100644
index 00000000..e90fd1fb
--- /dev/null
+++ b/docs/index-shard.md
@@ -0,0 +1,10 @@
+```java
+ /**
+ * 设置索引的分片数和副本数
+ *
+ * @param shards 分片数
+ * @param replicas 副本数
+ */
+settings(Integer shards, Integer replicas);
+```
+>**Tip:** 可根据实际服务器配置进行设置,合理的设置可提高综合效率和数据可靠性.
\ No newline at end of file
diff --git a/docs/index.html b/docs/index.html
new file mode 100644
index 00000000..f6a6fa5f
--- /dev/null
+++ b/docs/index.html
@@ -0,0 +1,147 @@
+
+
+
+
+
+ Easy-Es
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/index.md b/docs/index.md
new file mode 100644
index 00000000..a8266ac6
--- /dev/null
+++ b/docs/index.md
@@ -0,0 +1,15 @@
+> EE索引模块提供了如下API,供用户进行便捷调用
+> - indexName需要用户手动指定
+> - 对象 Wrapper 为 条件构造器
+
+```java
+ // 是否存在索引
+ Boolean existsIndex(String indexName);
+ // 创建索引
+ Boolean createIndex(LambdaEsIndexWrapper wrapper);
+ // 更新索引
+ Boolean updateIndex(LambdaEsIndexWrapper wrapper);
+ // 删除指定索引
+ Boolean deleteIndex(String indexName);
+```
+接口对应代码演示请根据名称点击大纲进入具体页面查看
\ No newline at end of file
diff --git a/docs/index_alias.md b/docs/index_alias.md
new file mode 100644
index 00000000..e69de29b
diff --git a/docs/insert.md b/docs/insert.md
new file mode 100644
index 00000000..6078ff57
--- /dev/null
+++ b/docs/insert.md
@@ -0,0 +1,15 @@
+```java
+// 插入一条记录
+Integer insert(T entity);
+
+// 批量插入多条记录
+Integer insertBatch(Collection entityList)
+```
+##### 参数说明
+| 类型 | 参数名 | 描述 |
+| --- | --- | --- |
+| T | entity | 实体对象 |
+| Collection | entityList | 实体对象集合 |
+
+> **Tips:**插入后如需id值可直接从entity中取,用法和MP中一致,批量插入亦可直接从原对象中获取插入成功后的数据id,以上接口返回Integer为成功条数
+
diff --git a/docs/isNotNull.md b/docs/isNotNull.md
new file mode 100644
index 00000000..1b0482e3
--- /dev/null
+++ b/docs/isNotNull.md
@@ -0,0 +1,7 @@
+```java
+isNotNull(R column)
+isNotNull(boolean condition, R column)
+```
+
+- 字段 IS NOT NULL
+- 例: isNotNull(Document::getTitle)--->title is not null
diff --git a/docs/isNull.md b/docs/isNull.md
new file mode 100644
index 00000000..29659f90
--- /dev/null
+++ b/docs/isNull.md
@@ -0,0 +1,7 @@
+```java
+isNull(R column)
+isNull(boolean condition, R column)
+```
+
+- 字段 IS NULL
+- 例: isNull(Document::getTitle)--->title is null
diff --git a/docs/le.md b/docs/le.md
new file mode 100644
index 00000000..69658815
--- /dev/null
+++ b/docs/le.md
@@ -0,0 +1,7 @@
+```java
+le(R column, Object val)
+le(boolean condition, R column, Object val)
+```
+
+- 小于等于 <=
+- 例: le("age", 18)--->age <= 18
diff --git a/docs/like.md b/docs/like.md
new file mode 100644
index 00000000..34ab4d3b
--- /dev/null
+++ b/docs/like.md
@@ -0,0 +1,7 @@
+```java
+like(R column, Object val)
+like(boolean condition, R column, Object val)
+```
+
+- LIKE '%值%'
+- 例: like("name", "王")--->name like '%王%'
diff --git a/docs/likeLeft.md b/docs/likeLeft.md
new file mode 100644
index 00000000..a7ae278c
--- /dev/null
+++ b/docs/likeLeft.md
@@ -0,0 +1,7 @@
+```java
+likeLeft(R column, Object val)
+likeLeft(boolean condition, R column, Object val)
+```
+
+- LIKE '%值'
+- 例: likeLeft("name", "王")--->name like '%王'
diff --git a/docs/likeRight.md b/docs/likeRight.md
new file mode 100644
index 00000000..74b893d5
--- /dev/null
+++ b/docs/likeRight.md
@@ -0,0 +1,7 @@
+```java
+likeRight(R column, Object val)
+likeRight(boolean condition, R column, Object val)
+```
+
+- LIKE '值%'
+- 例: likeRight("name", "王")--->name like '王%'
diff --git a/docs/limit.md b/docs/limit.md
new file mode 100644
index 00000000..6cc79bec
--- /dev/null
+++ b/docs/limit.md
@@ -0,0 +1,15 @@
+```java
+limit(Integer n);
+
+limit(Integer m, Integer n);
+```
+
+- limit n 最多返回多少条数据,相当于MySQL中limit n 中的n,用法一致.
+- limit m,n 跳过m条数据,最多返回n条数据,相当于MySQL中的limit m,n 或 offset m limit n
+- 例: limit(10)--->最多只返回10条数据
+- 例: limit(2,5)--->跳过前2条数据,从第3条开始查询,总共查询5条数据
+
+> **Tips:** n参数若不指定,则其默认值是10000 如果你单次查询,不想要太多得分较低的数据,需要手动指定n去做限制.
+
+> 另外此参数作用与Es中的size,from一致,只是为了兼容MySQL语法而引入,使用者可以根据自身习惯二选一,当两种都用时,只有一种会生效,后指定的会覆盖先指定的.
+
diff --git a/docs/lt.md b/docs/lt.md
new file mode 100644
index 00000000..60c59d33
--- /dev/null
+++ b/docs/lt.md
@@ -0,0 +1,7 @@
+```java
+lt(R column, Object val)
+lt(boolean condition, R column, Object val)
+```
+
+- 小于 <
+- 例: lt("age", 18)--->age < 18
diff --git a/docs/match.md b/docs/match.md
new file mode 100644
index 00000000..77e8d06c
--- /dev/null
+++ b/docs/match.md
@@ -0,0 +1,7 @@
+```java
+match(R column, Object val)
+match(boolean condition, R column, Object val)
+```
+
+- 分词匹配
+- 例: match("content", "老王")--->content 包含关键词 '老王' 如果分词粒度设置的比较细,老王可能会被拆分成"老"和"王",只要content中包含"老"或"王",均可以被搜出来
diff --git a/docs/ne.md b/docs/ne.md
new file mode 100644
index 00000000..fbb4ebee
--- /dev/null
+++ b/docs/ne.md
@@ -0,0 +1,7 @@
+```java
+ne(R column, Object val)
+ne(boolean condition, R column, Object val)
+```
+
+- 不等于 !=
+- 例: ne("name", "老王")--->name != '老王'
diff --git a/docs/notBetween.md b/docs/notBetween.md
new file mode 100644
index 00000000..067a619b
--- /dev/null
+++ b/docs/notBetween.md
@@ -0,0 +1,7 @@
+```java
+notBetween(R column, Object val1, Object val2)
+notBetween(boolean condition, R column, Object val1, Object val2)
+```
+
+- NOT BETWEEN 值1 AND 值2
+- 例: notBetween("age", 18, 30)--->age not between 18 and 30
diff --git a/docs/notIn.md b/docs/notIn.md
new file mode 100644
index 00000000..ca727147
--- /dev/null
+++ b/docs/notIn.md
@@ -0,0 +1,14 @@
+```java
+notIn(R column, Collection value)
+notIn(boolean condition, R column, Collection value)
+```
+
+- 字段 not in (value.get(0), value.get(1), ...)
+- 例: notIn("age",{1,2,3})--->age not in (1,2,3)
+```java
+notIn(R column, Object... values)
+notIn(boolean condition, R column, Object... values)
+```
+
+- 字段 not in (v0, v1, ...)
+- 例: notIn("age", 1, 2, 3)--->age not in (1,2,3)
diff --git a/docs/notLike.md b/docs/notLike.md
new file mode 100644
index 00000000..6c13c9ac
--- /dev/null
+++ b/docs/notLike.md
@@ -0,0 +1,7 @@
+```java
+notLike(R column, Object val)
+notLike(boolean condition, R column, Object val)
+```
+
+- NOT LIKE '%值%'
+- 例: notLike("name", "王")--->name not like '%王%'
diff --git a/docs/or.md b/docs/or.md
new file mode 100644
index 00000000..99d2b28c
--- /dev/null
+++ b/docs/or.md
@@ -0,0 +1,14 @@
+```java
+or()
+or(boolean condition)
+```
+
+- 拼接 OR**注意事项:**主动调用or表示紧接着下一个**方法**不是用and连接!(不调用or则默认为使用and连接)
+- 例: eq("Document::getId",1).or().eq(Document::getTitle,"Hello")--->id = 1 or title ='Hello'
+```java
+or(Consumer consumer)
+or(boolean condition, Consumer consumer)
+```
+
+- OR 嵌套
+- 例: or(i -> i.eq(Document::getTitle, "Hello").ne(Document::getCreator, "Guy"))--->or (title ='Hello' and status != 'Guy' )
diff --git a/docs/orderBy.md b/docs/orderBy.md
new file mode 100644
index 00000000..5495fa9a
--- /dev/null
+++ b/docs/orderBy.md
@@ -0,0 +1,6 @@
+```java
+orderBy(boolean condition, boolean isAsc, R... columns)
+```
+
+- 排序:ORDER BY 字段, ...
+- 例: orderBy(true, true, Document::getId,Document::getTitle)--->order by id ASC,title ASC
diff --git a/docs/orderByAsc.md b/docs/orderByAsc.md
new file mode 100644
index 00000000..d70dcbb2
--- /dev/null
+++ b/docs/orderByAsc.md
@@ -0,0 +1,7 @@
+```java
+orderByAsc(R... columns)
+orderByAsc(boolean condition, R... columns)
+```
+
+- 排序:ORDER BY 字段, ... ASC
+- 例: orderByAsc(Document::getId,Document::getTitle)--->order by id ASC,title ASC
diff --git a/docs/orderByDesc.md b/docs/orderByDesc.md
new file mode 100644
index 00000000..29f983d0
--- /dev/null
+++ b/docs/orderByDesc.md
@@ -0,0 +1,7 @@
+```java
+orderByDesc(R... columns)
+orderByDesc(boolean condition, R... columns)
+```
+
+- 排序:ORDER BY 字段, ... DESC
+- 例: orderByDesc(Document::getId,Document::getTitle)--->order by id DESC,title DESC
diff --git a/docs/origin-query.md b/docs/origin-query.md
new file mode 100644
index 00000000..a53c6805
--- /dev/null
+++ b/docs/origin-query.md
@@ -0,0 +1,11 @@
+```java
+ // 半原生查询
+ SearchResponse search(LambdaEsQueryWrapper wrapper) throws IOException;
+
+ // 标准原生查询 可指定 RequestOptions
+ SearchResponse search(SearchRequest searchRequest, RequestOptions requestOptions) throws IOException;
+```
+> Tips:
+> - 在一些高阶语法中,比如指定高亮字段,如果我们返回类型是实体对象本身,但实体中通常又没有高亮字段,导致高亮字段无法接收,此时可以用RestClietn原生的返回对象SearchResponse.
+> - 尽管EE覆盖了我们使用ES的绝大多场景,但仍可能存在没有覆盖到的场景,此时您仍可以通过RestClient提供的原生语法进行查询,调用标准原生查询方法即可,入参和返回均为RestClient原生
+
diff --git a/docs/origin_query.md b/docs/origin_query.md
new file mode 100644
index 00000000..7cd6c486
--- /dev/null
+++ b/docs/origin_query.md
@@ -0,0 +1 @@
+UpdateWrapper.md
\ No newline at end of file
diff --git a/docs/page.md b/docs/page.md
new file mode 100644
index 00000000..c2cbaa83
--- /dev/null
+++ b/docs/page.md
@@ -0,0 +1,18 @@
+```java
+ // 未指定返回类型,未指定分页参数(默认按当前页为1,总查询条数10条) 适合有高阶语法时的查询
+ PageInfo pageQueryOriginal(LambdaEsQueryWrapper wrapper) throws IOException;
+
+ // 未指定返回类型,指定分页参数 适合有高阶语法时的查询
+ PageInfo pageQueryOriginal(LambdaEsQueryWrapper wrapper, Integer pageNum, Integer pageSize) throws IOException;
+
+ // 指定返回类型,但未指定分页参数(默认按当前页为1,总查询条数10条)
+ PageInfo pageQuery(LambdaEsQueryWrapper wrapper);
+
+ // 指定返回类型及分页参数
+ PageInfo pageQuery(LambdaEsQueryWrapper wrapper, Integer pageNum, Integer pageSize);
+```
+> Tips:
+> - 无需集成任何插件,即可使用分页查询,本查询属于物理分页.
+> - 在一些高阶语法的使用场景中,由于有高亮,聚合等字段的返回,建议使用原生的SearchHit进行结果集的接收,否则由于实体中本身不含高亮及聚合等字段,会导致这类字段丢失.
+> - 注意PageInfo是由本框架提供的,如果你项目中已经有目前最受欢迎的开源分页插件PageHelper,请在引入包的时候注意别引入错误了,EE采用和PageHelper一样的返回字段,您无需担心字段名称不统一带来的额外工作量.
+
diff --git a/docs/particple.md b/docs/particple.md
new file mode 100644
index 00000000..da597431
--- /dev/null
+++ b/docs/particple.md
@@ -0,0 +1,12 @@
+分词查询是ES独有的,MySQL中不支持的一种查询,也就是你可以根据关键词进行匹配,关于分词查询这里不多介绍,不会的同学请自行百度了解概念,这里只介绍用法:
+```json
+ @Test
+ public void testMatch(){
+ // 测试分词查询
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "过硬";
+ wrapper.match(Document::getContent,keyword);
+ List documents = documentMapper.selectList(wrapper);
+ System.out.println(documents);
+ }
+```
diff --git a/docs/quick-start.md b/docs/quick-start.md
new file mode 100644
index 00000000..dfe7aacf
--- /dev/null
+++ b/docs/quick-start.md
@@ -0,0 +1,226 @@
+> **Tip**
+> 如果您用过Mybatis-Plus的话,您基本上可以无需多看此文档即可直接上手使用
+> Easy-Es是Mybatis-Plus在Elastic Search的平替版.
+
+
+我们将通过一个简单的 Demo 来阐述 Easy-Es 的强大功能,在此之前,我们假设您已经:
+
+- 拥有 Java 开发环境以及相应 IDE
+- 熟悉MySQL
+- 熟悉 Spring Boot
+- 熟悉 Maven
+- 了解Es基本概念
+- 已安装Es **推荐7.x+版本**(没有安装的可自行百度教程,建议再装一个es-head插件,便于可视化验证),低版本可能存在API不兼容或其它未知情况,因为底层采用RestHighLevelClient而非RestLowLevelClient,本Demo采用Es版本为7.10.0
+
+> **TIP**
+> 如果您懒得看下述教程,也可以下载[Springboo集成demo](quick-start.md)直接运行
+
+## 初始化工程
+
+---
+
+创建一个空的 Spring Boot 工程
+> **TIP**
+> 可以使用 [Spring Initializer](https://start.spring.io/)快速初始化一个 Spring Boot 工程
+
+##
+## 添加依赖
+
+---
+
+**Maven:**
+```xml
+
+ io.github.xpc1024
+ easy-es-boot-starter
+ Latest Version
+
+```
+**Gradle:**
+```groovy
+compile group: 'io.github.xpc1024', name: 'easy-es-boot-starter', version: 'Latest Version'
+```
+> **Tips:** Latest Version: [点此获取](https://img.shields.io/github/v/release/xpc1024/easy-es?include_prereleases&logo=xpc&style=plastic)
+
+
+## 配置
+
+---
+
+在 application.yml 配置文件中添加EasyEs必须的相关配置:
+```yaml
+easy-es:
+ enable: true #默认为true,若为false则认为不启用本框架
+ address : 127.0.0.1:9200 # es的连接地址,必须含端口 若为集群,则可以用逗号隔开 例如:127.0.0.1:9200,127.0.0.2:9200
+ username: elastic #若无 则可省略此行配置
+ password: WG7WVmuNMtM4GwNYkyWH #若无 则可省略此行配置
+```
+其它配置暂可省略,后面有章节详细介绍EasyEs的配置
+
+在 Spring Boot 启动类中添加 @EsMapperScan 注解,扫描 Mapper 文件夹:
+```java
+@SpringBootApplication
+@EsMapperScan("com.xpc.easyes.sample.mapper")
+public class Application {
+
+ public static void main(String[] args) {
+ SpringApplication.run(Application.class, args);
+ }
+
+}
+```
+## 背景
+
+---
+
+现有一张Document文档表,随着数据量膨胀,其查询效率已经无法满足产品需求,其表结构如下,我们打算将此表内容迁移至Es搜索引擎,提高查询效率
+
+| id | title | content |
+| --- | --- | --- |
+| 主键 | 标题 | 内容 |
+
+## 编码
+
+---
+
+编写实体类Document.java(此处使用了 [Lombok](https://www.projectlombok.org/)简化代码)
+```java
+@Data
+public class Document {
+ /**
+ * es中的唯一id
+ */
+ private String id;
+ /**
+ * 文档标题
+ */
+ private String title;
+ /**
+ * 文档内容
+ */
+ private String content;
+}
+```
+> Tips: 上面字段id如果未进行任何注解和全局配置,则其策略默认为Es自动生成,在es中对应字段'_id',字段类型为String,如果您需要对id进行特殊处理,后续章节有介绍如何对Id进行配置.
+
+编写Mapper类 DocumentMapper.java
+```java
+public interface DocumentMapper extends BaseEsMapper {
+}
+```
+## 开始使用(CRUD)
+
+---
+
+添加测试类,进行功能测试:
+> **前置操作:** 创建索引(相当于MySQL中的一张表,先有表才能进行后续CRUD)
+
+```java
+import com.xpc.easyes.core.enums.FieldType;
+@SpringBootTest(classes = EasyEsApplication.class)
+public class SearchTest {
+
+ @Resource
+ DocumentMapper documentMapper;
+
+ @Test
+ public void testCreatIndex() {
+ // 测试创建索引 不了解Es索引概念的建议先去了解 懒汉可以简单理解为MySQL中的一张表
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+
+ // 此处简单起见 直接使用类名作为索引名称 后面章节会教大家更如何灵活配置和使用索引
+ wrapper.indexName(Document.class.getSimpleName().toLowerCase());
+
+ // 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型(支持分词查询)
+ wrapper.mapping(Document::getTitle, FieldType.KEYWORD)
+ .mapping(Document::getContent, FieldType.TEXT);
+
+ boolean isOk = documentMapper.createIndex(wrapper);
+ Assert.assertTrue(isOk);
+ // 期望值: true 如果是true 则证明索引已成功创建
+ }
+
+}
+```
+> 测试新增: 新增一条数据(相当于MySQL中的Insert操作)
+
+```java
+ @Test
+ public void testInsert() {
+ // 测试插入数据
+ Document document = new Document();
+ document.setTitle("老汉");
+ document.setContent("推*技术过硬");
+ String id = documentMapper.insert(document);
+ System.out.println(id);
+ }
+```
+> 测试查询:根据条件查询指定数据(相当于MySQL中的Select操作)
+
+```java
+ @Test
+ public void testSelect() {
+ // 测试查询
+ String title = "老汉";
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.eq(Document::getTitle,title);
+ Document document = documentMapper.selectOne(wrapper);
+ System.out.println(document);
+ Assert.assertEquals(title,document.getTitle());
+ }
+```
+> 测试更新:更新数据(相当于MySQL中的Update操作)
+
+```java
+ @Test
+ public void testUpdate() {
+ // 测试更新 更新有两种情况 分别演示如下:
+ // case1: 已知id, 根据id更新 (为了演示方便,此id是从上一步查询中复制过来的,实际业务可以自行查询)
+ String id = "krkvN30BUP1SGucenZQ9";
+ String title1 = "隔壁老王";
+ Document document1 = new Document();
+ document1.setId(id);
+ document1.setTitle(title1);
+ documentMapper.updateById(document1);
+
+ // case2: id未知, 根据条件更新
+ LambdaEsUpdateWrapper wrapper = new LambdaEsUpdateWrapper<>();
+ wrapper.eq(Document::getTitle,title1);
+ Document document2 = new Document();
+ document2.setTitle("隔壁老李");
+ document2.setContent("推*技术过软");
+ documentMapper.update(document2,wrapper);
+
+ // 关于case2 还有另一种省略实体的简单写法,这里不演示,后面章节有介绍,语法与MP一致
+ }
+```
+经过一顿猛如虎的更新操作 我们来看看标题最终变成了什么?
+
+
+
+查询结果证实了我们更新没有问题,这里无意冒犯"老李",仅供演示,如有得罪,请海涵.
+
+> 测试删除:删除数据(相当于MySQL中的Delete操作)
+
+```java
+ @Test
+ public void testDelete() {
+ // 测试删除数据 删除有两种情况:根据id删或根据条件删
+ // 鉴于根据id删过于简单,这里仅演示根据条件删,以老李的名义删,让老李心理平衡些
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String title = "隔壁老李";
+ wrapper.eq(Document::getTitle,title);
+ int successCount = documentMapper.delete(wrapper);
+ System.out.println(successCount);
+ }
+```
+> **TIP**
+> 下面完整的代码示例请移步:[Easy-Es-Sample](https://gitee.com/easy-es/easy-es/tree/master/easy-es-sample/src/test/java/com/xpc/easyes/sample/test)
+
+## 小结
+
+---
+
+通过以上几个简单的步骤,我们就实现了 Document的索引创建及CRUD 功能,最终也帮老李洗白了.
+从以上步骤中,我们可以看到集成Easy-Es非常的简单,只需要引入 starter 工程,并配置 mapper 扫描路径即可。
+但Easy-Es 的强大远不止这些功能,想要详细了解 Easy-Es 的强大功能?那就继续往下看吧!
diff --git a/docs/sceen.md b/docs/sceen.md
new file mode 100644
index 00000000..2b8fd6d6
--- /dev/null
+++ b/docs/sceen.md
@@ -0,0 +1,26 @@
+
+
+1. 检索类服务
+- 搜索文库
+- 电商商品检索
+- 海量系统日志检索
+
+
+
+2. 问答类服务(本质上也是检索类)
+- 在线智能客服
+- 机器人
+
+
+
+3. 地图类服务
+- 打车app
+- 外卖app
+- 社区团购配送
+- 陌生人社交
+
+
+
+...
+
+以上只是我个人能想到的一些应用场景,实际上Easy-Es的API基本上覆盖了Elastic Search 90%以上的功能,99%以上的常用功能,所以您可以基于EE快速构建出各种系统,即便是十分复杂多变的查询,也可以从容应对,Trust me!
diff --git a/docs/select.md b/docs/select.md
new file mode 100644
index 00000000..1fb659ba
--- /dev/null
+++ b/docs/select.md
@@ -0,0 +1,19 @@
+```java
+ // 获取总数
+ Long selectCount(LambdaEsQueryWrapper wrapper);
+ // 根据 ID 查询
+ T selectById(Serializable id);
+ // 查询(根据ID 批量查询)
+ List selectBatchIds(Collection idList);
+ // 根据动态查询条件,查询一条记录 若存在多条记录 会报错
+ T selectOne(LambdaEsQueryWrapper wrapper);
+ // 根据动态查询条件,查询全部记录
+ List selectList(LambdaEsQueryWrapper wrapper);
+```
+##### 参数说明
+| 类型 | 参数名 | 描述 |
+| --- | --- | --- |
+| Wrapper | queryWrapper | 实体包装类 QueryWrapper |
+| Serializable | id | 主键ID |
+| Collection | idList | 主键ID列表 |
+
diff --git a/docs/set.md b/docs/set.md
new file mode 100644
index 00000000..419189a8
--- /dev/null
+++ b/docs/set.md
@@ -0,0 +1,9 @@
+```java
+set(String column, Object val)
+set(boolean condition, String column, Object val)
+```
+
+- SQL SET 字段
+- 例: set("name", "老李头")
+- 例: set("name", "")--->数据库字段值变为**空字符串**
+- 例: set("name", null)--->数据库字段值变为null
diff --git a/docs/size.md b/docs/size.md
new file mode 100644
index 00000000..b4f35448
--- /dev/null
+++ b/docs/size.md
@@ -0,0 +1,9 @@
+```java
+size(Integer size)
+```
+
+- 最多返回多少条数据,相当于MySQL中limit (m,n)中的n 或limit n 中的n
+- 例: size(10)--->最多只返回10条数据
+> **Tips:**size参数若不指定,则其默认值是10000
+> 如果你单次查询,不想要太多得分较低的数据,需要手动指定size去做限制.
+
diff --git a/docs/sort.md b/docs/sort.md
new file mode 100644
index 00000000..d18ce823
--- /dev/null
+++ b/docs/sort.md
@@ -0,0 +1,23 @@
+针对字段的排序,支持升序排序和降序排序:
+```java
+// 降序排列
+wrapper.orderByDesc(排序字段,支持多字段)
+// 升序排列
+wrapper.orderByAsc(排序字段,支持多字段)
+```
+使用示例:
+```java
+ @Test
+ public void testSort(){
+ // 测试排序 为了测试排序,我们在Document对象中新增了创建时间字段,更新了索引,并新增了两条数据
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ wrapper.likeRight(Document::getContent,"推");
+ wrapper.select(Document::getTitle,Document::getGmtCreate);
+ List before = documentMapper.selectList(wrapper);
+ System.out.println("before:"+before);
+ wrapper.orderByDesc(Document::getGmtCreate);
+ List desc = documentMapper.selectList(wrapper);
+ System.out.println("desc:"+desc);
+ }
+```
+效果: 
diff --git a/docs/source.md b/docs/source.md
new file mode 100644
index 00000000..54944a7e
--- /dev/null
+++ b/docs/source.md
@@ -0,0 +1,12 @@
+```java
+// 获取通过本框架生成的查询参数 可用于检验本框架生成的查询参数是否正确
+String getSource(LambdaEsQueryWrapper wrapper);
+```
+##### 参数说明
+| 类型 | 参数名 | 描述 |
+| --- | --- | --- |
+| Wrapper | updateWrapper | 实体对象封装操作类 UpdateWrapper |
+
+> Tips:
+> 生产环境可以在调用本框架查询之前,先调用此接口,将获取到的查询参数(JSONString)记录进日志,以便在出现问题时排查是否框架本身生成的查询入参有误. 当然后期稳定版本中我们会将此方法废弃,因为就目前来看存在的意义也不大,经过大量测试,框架生成的查询参数都没有发现任何问题.
+
diff --git a/docs/thanks.md b/docs/thanks.md
new file mode 100644
index 00000000..c4f20cfe
--- /dev/null
+++ b/docs/thanks.md
@@ -0,0 +1,22 @@
+> 这里特别鸣谢国内最受欢迎的MySQL开源框架[Mybatis-Plus](https://mp.baomidou.com/)的作者及所有参与开发者.
+
+> 鸣谢ElasticeSearch官方打造的开源框架[RestHighLevelClient](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/index.html)
+的作者及其所有参与开发者.
+
+> 感谢协助本人将语雀中数量庞大的[Easy-Es英文文档](https://www.yuque.com/laohan-14b9d/tald79/qf7ns2)悉数迁移至本站的"清风徐飘"先生,由衷感谢!
+
+> 感谢璐先生为本站捐赠宝贵的服务器资源,并贡献了颇具价值的前置拦截器插件功能,该功能由璐先生独立开发,预计将在0.9.7版本上线.
+
+
+感谢你们开源如此强大又好用的框架,由此带来国内外无数开发者的解放,大幅提高了开发搬砖效率,由此给众多开发者节省了大量宝贵时间.也给我提供了创作灵感,可以说没有Mybatis-Plus就没有Easy-Es,当然未来也或许会有,但起码不会这么快和大家见面,也或许是其它作者开发. Mybatis-Plus和Easy-Es的关系,就像F22和歼20的关系,在框架开发的过程中,无论是为了兼容语法还是一些未知点的突破,MP都给予了恰到好处的指引,让我少走了很多弯路,把别人好几年走完的路,作为起点,站在巨人的肩膀上,由此打造出一款还算好用的Es开发框架,尽管目前还无法与MP相提并论,但我相信未来终会有一天,EE也可以成为国内最受欢迎的ES开源框架.
+
+为了保持与MP99%相似度的语法,EE框架在开发过程中大量借鉴了MP源码,如果不深入底层看,仅看接口定义,会误以为是复制粘贴MP接口,但底层逻辑终究是不一样的,MP最终是将语法转换成String SQL, 而EE最终是将语法转换成JSON类型的ES语法,本质上还是有挺大差别,这里面依旧有很多创新点和难点需要突破,期间有几个难点,一度让我产生放弃的念头,还好最后通过各种努力和思考,以及坚持不懈,完成了整个框架的开发,测试,文档撰写等.
+
+现在,我将此框架源码开源献给全球所有开发者,毕竟凝聚了国内外各路优秀开发者的思路,那才有可能打造真正的"Easyest",否则它只能是Easy-ES.
+
+如果本框架有在开发过程中帮您提高开发效率,节省了开发时间,不妨花几秒钟时间(打造此框架前后耗费大量光阴)给本框架在Git点个Star,让更多人看到并用到它,不做拿来主义者,从我做起!
+
+最后感谢您能阅读到这里,也感谢您对EE的支持,谢谢!
+
+by老汉
+
diff --git a/docs/update-index.md b/docs/update-index.md
new file mode 100644
index 00000000..3244123d
--- /dev/null
+++ b/docs/update-index.md
@@ -0,0 +1,19 @@
+在很多场景下,由于实体模型或需求的变动,我们需要对索引进行更新,例如,我在文档实体模型中新增了一个作者字段creator,此时我想更新索引,以便能够根据作者关键字进行搜索:
+```java
+ @Test
+ public void testUpdateIndex(){
+ // 测试更新索引
+ LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper<>();
+ // 指定要更新哪个索引
+ String indexName = Document.class.getSimpleName().toLowerCase();
+ wrapper.indexName(indexName);
+ wrapper.mapping(Document::getCreator,FieldType.KEYWORD);
+ boolean isOk = documentMapper.updateIndex(wrapper);
+ Assert.assertTrue(isOk);
+ }
+```
+> **Tips:**
+> - 如果您的生产环境需要平滑过渡,那么我们不建议用此方式更新索引,因为更新mapping会导致Es重建索引,此类情形下,建议通过别名alias的方式进行迁移
+> - indexName不能为空,必须指定要更新哪个索引
+> - 本接口仅支持更新索引的mapping,如需更新分片,数据集,索引名称等信息,建议可调用删除索引接口删除原索引,然后调用索引创建接口重新创建索引(低频操作,后期版本可根据用户反馈决定是否加入支持更新)
+
diff --git a/docs/update-log.md b/docs/update-log.md
new file mode 100644
index 00000000..de992e03
--- /dev/null
+++ b/docs/update-log.md
@@ -0,0 +1,19 @@
+~~0.9.0 初次发布至Maven中央仓库,由于缺乏经验,导致项目虽然正常推至中央仓库,但无法通过IDE下载(会报错)~~
+
+~~0.9.1 调整了项目分层结构,修复了上一版本无法通过IDE下载的问题.~~
+
+~~0.9.2 修复了上一版本由fastjson(~~[~~1.2.62~~](https://github.com/alibaba/fastjson/issues/2780)~~)本身的缺陷带来的查询报错问题.~~
+
+~~0.9.3 重命名了启动模块,启动模块原名称英文单词打错了,新增了英文文档.~~
+
+~~0.9.4 修复用户提出的issue,配置项新增Es性能配置参数等更多配置项~~
+
+~~0.9.5 升级fastjson至最新版本,新增创建/更新索引分词器功能,新增地理位置相关的所有功能,非常强大!~~
+
+~~0.9.6 修复物理分页指定size后不生效的问题,更新接口引入本地缓存,进一步提升性能,新增性能测试模块,新增用户自定义数据id功能,新增对混合查询模式的使用文档~~
+
+持续更新中...
+
+> **Tip**
+> 已发布的版本会被用删除线标记
+
diff --git a/docs/update-plan.md b/docs/update-plan.md
new file mode 100644
index 00000000..39de3a8d
--- /dev/null
+++ b/docs/update-plan.md
@@ -0,0 +1,44 @@
+## 版本更新计划
+> 版本规划中需求为
+
+- ~~0.9.4 (2022年1月上旬前,已发布)~~
+ 1. ~~新增es配置项,可以灵活配置请求超时时间,最大连接数等一系列深度配置~~
+ 1. ~~修复查询列表时,id为同一个的缺陷~~
+ 1. ~~修复查询条件为in/notIn查询条件未生效的缺陷~~
+ 1. ~~设置默认查询条目数为1w条~~
+ 1. ~~文档更新,引入查询条目数说明及如何设置~~
+- ~~0.9.5 (2022年4月前,大部分核心功能已提前发布)~~
+ 1. ~~优化代码中一切可以优化的地方~~
+ 1. ~~引入Lambda风格地理位置查询api~~
+ 1. 引入自动创建索引模块,索引可配置策略是否自动创建,用户可灵活选择自动托管还是手动创建.
+
+@2022-02-16 此需求因es索引更新会导致重建问题(核心原因),合理性待后续评估,暂时延后待排期
+
+ 4. 增强原@TableField字段注解,引入mapping类型的自动映射和手动指定,分词器指定等.
+
+@2022-02-16 时间原因延期,此需求因es索引更新会导致重建问题(核心原因),合理性待后续评估,暂时延后待排期,已发布通过API方式指定和更新分词器功能作为平替版. ~~本版本已上线通过API方式指定和更新分词器,作为此功能的平替版先上线了~~
+
+- ~~0.9.6(2022年3月中旬前)~~
+ 1. ~~引入性能测试模块~~
+ 1. ~~接口功能测试覆盖率100% (已完成)~~
+ 1. ~~修缮所有被反馈或者存在缺陷或设计不合理的地方~~
+ 1. ~~文档更新,引入顾虑粉碎模块(已提前发布)~~
+ 1. ~~ID支持用户自定义传入,由GITEE网友@~~[~~青山~~](https://gitee.com/luoqy)~~在2月提出,这样可以在插入数据时,如果ID重复,则自动更新文档,ID不重复时才新增. (此需求合理性待大家评估.目前已提供了UUID和ES默认ID两种ID生成方式)~~
+ 1. ~~新增混合查询文档,帮助用户解决EE功能不支持问题~~
+- 0.9.7(2022年6月前,有功能可能提前发布,有功能可能延后至下迭代,但大的时间线不会变)
+ 1. 聚合模块功能支持更多ES独有的聚合功能 答疑群内网友提出
+ 1. 聚合功能进一步强化,支持更多种类型的聚合
+ 1. 地理位置查询的排序功能进一步强化,支持更多场景
+ 1. 提供多数据源的支持(答疑群内用户"极光"提出)
+ 1. 提供对主键的多类型支持(Integer,Long等,不需要转为String,群内"大仙儿"提出)
+ 1. 对or(),or(Function func)进一步优化,提升用户体验
+ 1. 引入插件Module,开发者可以定制自己所需插件,开发者自定义,目前该模块已有贡献者一个插件 @璐先生,代码在dev分支,喜欢尝鲜的用户可以下载尝试,该插件主要提供AOP前置拦截增强功能. 也欢迎更多开发者来贡献插件
+
+## 需求池
+> 需求池中需求待排期,看迭代规划,择期上线
+
+ 1. xpack本地秘钥型权限校验模块配置功能 由网友@周立波邮件本人提出此需求支持
+ 1. Percolate反向检索支持,由GItee用户Earl提出
+ 1. 通过自定义注解懒人一键托管索引功能,支持通过配置开启/关闭此功能
+
+- 持续更新中...
diff --git a/docs/update.md b/docs/update.md
new file mode 100644
index 00000000..d64c7a7a
--- /dev/null
+++ b/docs/update.md
@@ -0,0 +1,17 @@
+```java
+//根据 ID 更新
+Integer updateById(T entity);
+
+// 根据ID 批量更新
+Integer updateBatchByIds(Collection entityList);
+
+// 根据动态条件 更新记录
+Integer update(T entity, LambdaEsUpdateWrapper updateWrapper);
+```
+##### 参数说明
+| 类型 | 参数名 | 描述 |
+| --- | --- | --- |
+| T | entity | 实体对象 |
+| Wrapper | updateWrapper | 实体对象封装操作类 UpdateWrapper |
+| Collection | entityList | 实体对象集合 |
+
diff --git a/docs/weight.md b/docs/weight.md
new file mode 100644
index 00000000..108e5802
--- /dev/null
+++ b/docs/weight.md
@@ -0,0 +1,22 @@
+权重查询也是Es有MySQL无的一种查询,语法如下:
+```java
+function(字段, 值, Float 权重值)
+```
+```java
+ @Test
+ public void testWeight() throws IOException {
+ // 测试权重
+ LambdaEsQueryWrapper wrapper = new LambdaEsQueryWrapper<>();
+ String keyword = "过硬";
+ float contentBoost = 5.0f;
+ wrapper.match(Document::getContent,keyword,contentBoost);
+ String creator = "老汉";
+ float creatorBoost = 2.0f;
+ wrapper.eq(Document::getCreator,creator,creatorBoost);
+ SearchResponse response = documentMapper.search(wrapper);
+ System.out.println(response);
+ }
+```
+> **Tips:**
+> 如果你需要得分,则通过SearchResponse返回,如果不需要得分,只需要按照得分高的排名靠前返回,则直接用List接收即可.
+
diff --git a/docs/worry-free.md b/docs/worry-free.md
new file mode 100644
index 00000000..cdcc265f
--- /dev/null
+++ b/docs/worry-free.md
@@ -0,0 +1,77 @@
+# 1.性能
+
+---
+
+
+在正式接入Easy-Es至生产环境之前,您肯定会担心一个问题,就是使用此框架后,系统的查询效率是否会变低?系统资源开销是否会变大?负面影响到底有多少?
+这些问题关乎到一个框架的存活,作为EE作者,这些问题我在开发前就考虑到了,但用户并不知晓,所以我再此一一帮您粉碎这些顾虑.
+
+
+
+我们先来看EE在整个查询过程中做了什么事? 总结起来就2件:
+
+
+
+1. 把用户输入的MySQL语法(Mybatis-Plus语法)转换成RestHighLevel语法,然后调用RestHighLevelClient执行本次查询
+
+1. 把查询结果转换成用户想要的格式:如List并返回.
+
+
+- 其中,语法转换是按照[MySQL和RestHighLevelClient语法对照表](compare.md)的关系进行转换.这种转换其实耗费的性能非常低,因为即使你直接使用RestHighLevelClient进行查询,你依旧需要创建出termQueryBuilder和BoolQueryBuilder. 唯一的区别就是我把用户输入的查询条件eq放入了队列,然后通过队里FIFO(除查询条件中有or的情况)的顺序逐一进行转换,对于绝大多数查询语句,查询条件都不会太多,所以队里中的元素数大多数情况下都会小于10,而且队列中我只存了枚举和参数,既不会占用过多内存,也不会因为队列的遍历消耗多少性能. 对于现代计算机而言,别说遍历10条小数据,就是成百上千条也是毫秒级的,所以这点性能损耗基本可以忽略不计
+
+- 再说结果解析,结果解析其实就是把调用RestHighLevelClient返回的SearchResponse中的hits取出并用fastJson转换成数组,这个过程就算不用EE,你直接用RestHighLevelClient也是会有这一步,所以这一步并没有过多的损耗,即便是我用了反射,字段的反射和注解信息,都在框架启动时加载进内存中了,做了jvm的缓存,所以这点损耗可忽略不计.
+
+
+当然如上都是基于理论分析,在0.9.6版本中,Sample模块的test目录Performance测试类中,大家可以看到我针对CURD分别作了不同维度的性能测试,实际测试的结果也很好的印证了我上面的理论分析,EE除了查询会比直接使用RestHighLevelClient平均慢10-15毫秒,增删改API并无差异,而且随着查询数据量的增大,实体字段缓存生效后,查询差异会进一步降低,几乎可以忽略不计. 牺牲10毫秒,对用户而言是无感知的,但对开发而言,可以节省大量代码和时间,我认为这是值得的,基本上没有哪款ORM框架是不会损耗性能的,权衡利弊,主公们心理应该都会有答案.
+
+
+# 2.安全
+
+---
+
+本框架所有三方依赖有elastic search官方提供的es操作套件和RestHighLevelClient,阿里的fastJson,Spring官方的SpringbootAutoConfig,Apache的commons-codec以及Lombok,无二方依赖,空口黄牙,口说无凭,大家可以点开maven中央仓库,亲自查看一番:[maven中央仓库](https://search.maven.org/search?q=easy-es)
+以上套件即使不使用EE,你在实际开发中也会用到,且都是官方出品,所以您无需担心.
+那么EE有没有可能有安全问题?毕竟是个人开发者写的,没有前面提到的框架那么强的背书.首先我认为任何框架都有可能有安全风险,即便是有强大的公司背书,比如前阵子阿里fastjson的安全漏洞. 对于EE,我个人认为目前不会有特别严重的安全问题,EE框架的核心原理上面的图中已经列出来了,EE的核心原理只是转换,相当于一个翻译或者中介,并无其它涉及安全类的操作,加上EE框架本身十分轻量,没有引入任何多余的类库,所有工具类都是自己封装,封装的时候也参照了apache工具类,所以有理由认为使用EE是相对安全的,除非下游的官方依赖本身有安全漏洞. 如质疑框架本身存在安全问题的,大可以下载源码阅读一番,看看有无漏洞.
+
+
+# 3.拓展性
+
+---
+
+
+EE底层用的就是Es官方提供的RestHighLevelClient,我们只是对RestHighLevelClient做了增强,并没有改变减少或是削弱它原有的功能,所以您无需担心拓展性.
+任何框架的使用都会降低系统的灵活性,因为框架是死的,使用了以后不可避免的会碰到一些场景框架无法满足,需要定制化开发,或是短期内您不了解框架本身,不敢贸然使用,不然以后遇到问题怎么办?
+为了解决上述问题,我特地在框架中留了[混合查询](hybrid-query.md)和[原生查询](origin-query.md)
+目前EE提供的所有API可以覆盖实际开发中99%的需求,当极小概率下1%的需求无法覆盖时,您可以通过使用混合查询,也就是能支持的语句用EE生成,不能支持的语句就直接用RestHighLevelClient的语法,然后通过原生接口去完成查询,既简单有省事.当然如果您不喜欢这种"油电混动"的方式,您也可以直接用原生查询接口去完成查询,和直接使用RestHighLevelClient一样.
+当然如果您实在不想用EE提供的任何方法,EE仍可以作为一个自动配置版的RestHighLevelClient使用,直接在需要的地方注入RestHighLevelClient进行使用即可,EE已经帮您把RestHighLevelClient按照您在配置文件中指定配置,自动装配成SpringBean了,所以在任何情况下,您都可以很自信很从容,就像直接使用官方的RestHighLevelClient一样,根本不需要担心有一天出问题了怎么办,大不了不用EE,只把它当成一个引入依赖和自动配置的工具.而且这种可能性也非常的低,我们还有专门的答疑群无偿在线给予您支持,对您的合理需求也会第一时间响应并安排落地.
+
+
+# 4.团队及社区活跃度
+
+---
+
+
+团队目前招募到了5人,我称之为"五虎上将",从0.9.5+的版本之后开始TeamWork,未来随着项目发展还会招募更多有志之士加入,社区目前活跃,每年会发很多个版本,不断提升用户体验,对于用户提的需求会在一周内响应,合理的会在一个月内立项,三个月内完成开发上线.Issue类问题确认后会在两周内解决并上线.
+
+
+# 5.接入优势
+
+---
+
+
+- 简单易用高效不用我多说了吧,MyBatis-Plus用户懂的都懂! 大把的时间节省出来,做...爱做的事情,真香!
+- 使用门槛降低,就算是刚不懂Es的小白,也可以用EE开发各种功能
+- 大幅减少代码量,提升代码可读性,降低重复代码量,提升代码质量
+- 专业答疑团队,无忧售后
+- 永久免费
+
+...
+
+
+# 6.结语
+
+---
+
+
+新能源汽车刚出来的时候,油车车主还在观望,先上车的已经体验到甜头了,好不好用了就知道,至于那些所谓的问题,都会随着时间被解决,多尝试新鲜事物,拥抱变化,不因循守旧,不用一成不变的观念来看瞬息万变的世界,才能立于不败之地.
+